15. Appendix¶
15.1. AWS IoT Core¶
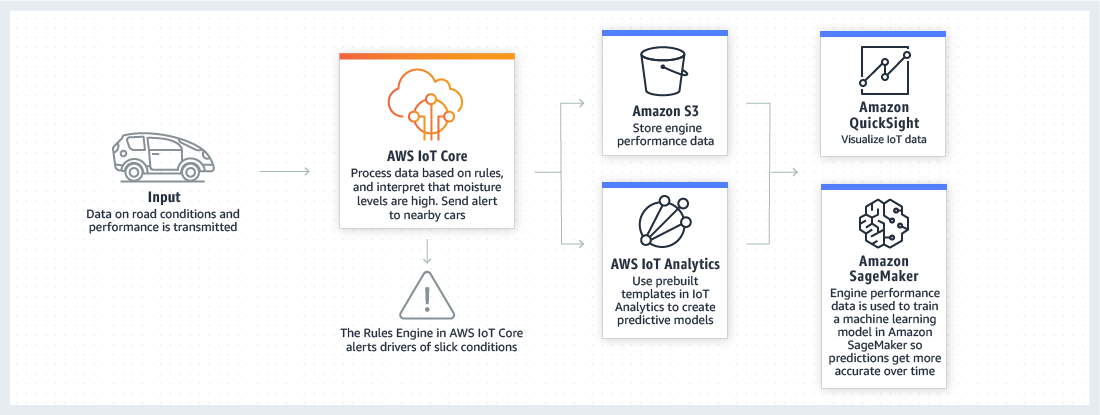
AWS IoT Core is a managed cloud service that lets connected devices easily and securely interact with cloud applications and other devices. AWS IoT Core provides secure communication and data processing across different kinds of connected devices and locations so you can easily build IoT applications.
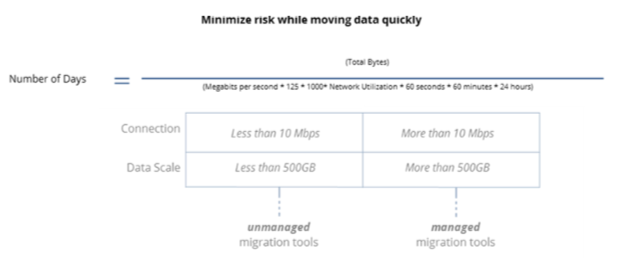
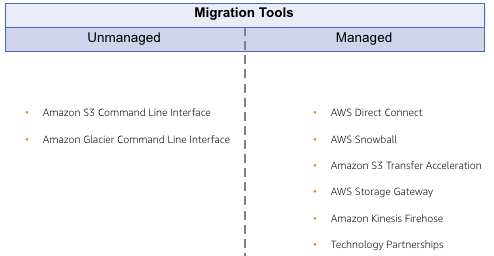
15.3. Cloud Economics¶
The cloud economics offering support AWS APN Partners in multiple areas, including business value and cloud financial management. For business value, the cloud value framework consists of 4 pillars:
- Cost savings (typical focus)
- Staff productivity
- Operational resilience
- Business agility
The last 3 being the most compelling cloud benefits.
The cloud financial management offering is to make sure customers reap the cost benefits associated with running their workloads on AWS.
15.3.1. Cost savings¶
See section AWS pricing
15.3.2. Staff productivity¶
As enterprises move to AWS, a few common patterns emerge at the IT staff level. Tactical, undifferentiated work previously required for traditional data centers, like provisioning resources, moves from manual to automated. This saves staff time and reduces time to market. This allows customers’ resurces to move to more strategic work.
As AWS maturity increases, customers learn how to further improve their businesses with AWS. They adopt new services and technologies, which can result in additional cost reductions and accelerated time to market.
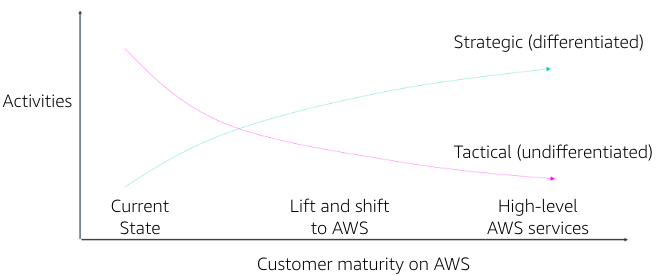
AWS maturity versus activities
IT team members who used to work on projects like storage array deployments and server refreshes can transition to become DevOps specialists. By being integrated into the dev team, they can support the development of new products and services.
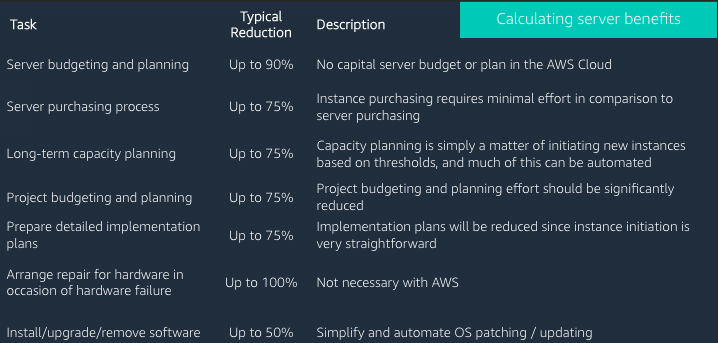
Server benefits

Network benefits
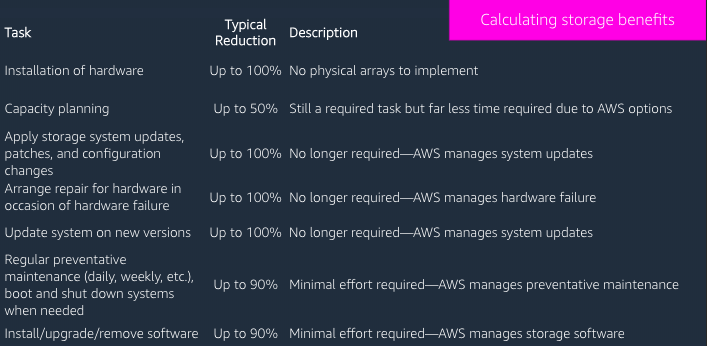
Storage benefits

Application benefits

Facilities benefits

Security benefits
15.3.3. Operational resilience¶
Operational resilient IT organizations depend on the health of 4 cornerstones: operations, security, software, and infrastructure.
15.3.3.1. Operations failures¶
Some primary causes of operations failures are:
- Human errors, such as lack of clearly defined procedures or user privilege.
- Configuration errors in hardware or operating system settings and startup scripts.
- Procedural errors, like restoring the wrong backup or forgetting to restart a device.
- Commonplace accidents in the data center, like tripping over power cords, dropping equipment, or disconnecting devices.
AWS leverages automation; manages services from end to end; provides system-wide visbility for usage, performance, and operational metrics; enables security and governance configuration; and monitors API access.
15.3.3.2. Security: causes for breaches¶
The causes for security breaches include:
- Malware, such as worms, viruses, and trojan horses.
- Network attacks, like open ports, SYN floods, and fragmented packets.
- Unpatched applications or operating systems.
- Security issues, such as password disclosures, social engineering, credentials not stored securely, non-strict password policies, and poor privilege and access management.
- Poor or limited authentication.
AWS has a Shared Responsibility Model, which means that AWS shares security responsibilities with customers. In this model, AWS is responsible for the security of everything from the hypervisor level to the operating system.
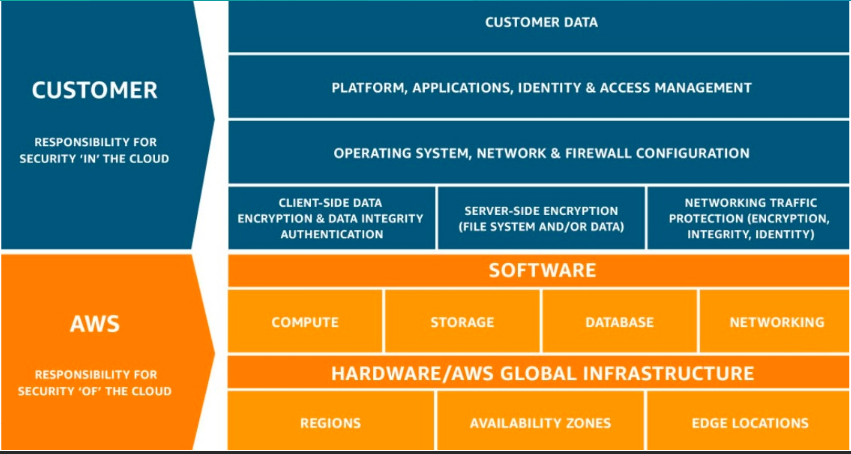
AWS shared security model
AWS managed services move the line of responsibility higher.
AWS helps to reduce security risks in numerous ways:
- Leverages AWS automation and tools available to help customers mitigate the most severe security risks, including denial of service attacks.
- Provides the AWS Identity Access Management (IAM), service to centrally manage users and credentials, which helps customers reduce or eliminate the existence of “rogue servers”.
- Leverages our roster of 30 plus compliance certifications and accreditations to help our customers build secure, compliance-ready environment.
15.3.3.3. Software: causes for failure¶
Common causes for software resilience failures include:
- Resource exhaustion, like runaway processes, memory leaks, and file growth.
- Computational or logic errors, such as faulty references, de-allocated memory, corrupt pointers, sync errors, and race conditions.
- Inadequate monitoring, such as the inability to identify issues.
- Failed upgrades, such as intercompatibility and integrations.
AWS provides services in a way that allows customers to increase or decrease the resources they need and have AWS manage the changes. To provide software resilence, AWS:
- Offer blue and green deployments that allow for quick rollbacks.
- Automates continuous integration and continuous delivery workflow.
- Runs smaller code deployments to reduce unit, integration, and system bugs.
- Provides current and secure resources with OS patching.
- Creates and manages a collection of related AWS resources.
15.3.3.4. Infrastructure: causes for failure¶
Causes for infrastructure failure include:
- Hardware failure of servers, storage, or networks.
- Natural disaster, like hurricanes, floods, and earthquakes.
- Power outages, including failed power supplies and batteries.
- Volumetric attacks, such as DDoS, DNS amplification; or UDP/ICMP floods.
AWS helps reduce infrastructure failures in numerous ways:
- AWS continues to expand their world-class infrastructure and leads the industry in improving data centers on a massive scale.
- Customers can run applications and failover across multiple Availability Zones and Regions.
- AWS systems are designed to be highly available and durable. S3 is designed to provide eleven 9s of durability and four 9s of availability. Amazon Ec2 is designed for four 9s of availability, and Amazon EBS volumes are designed for five 9s of availability.
- As a standard, each AWS Availability Zone in each Region is redundantly connected to multiple tier-one transit providers.
- At AWS every compute instance is served by two independent power sources, each with utility, UPS, and back-up generator power.
15.3.4. Business agility¶
Here, you can see a list of KPIs for measuring business agility:

15.3.4.1. Time to market for new applications¶
Some of the most important activities that a healthy business must do to continue to grow and innovate are to scope, prioritize, and take on new initiatives. You can think about the initiative process like a project funnel.
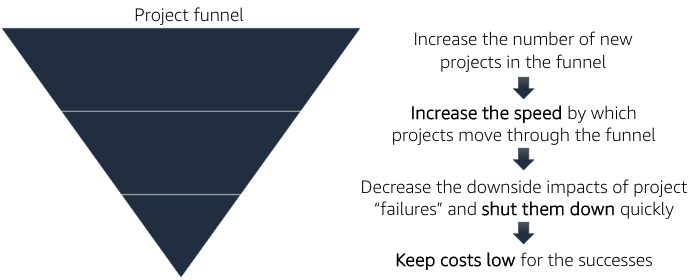
Innovate by increasing “fail fast” while reducing risks and costs
15.3.4.2. Code throughput and systems stability¶
DevOps practices help customers deliver software faster, more reliably, and with fewer errors. Two key DEvOps- related IT performance dimensions are code throughput and systems stability.
Lead time for changes and deployment frequency correspond to code throughput. Throughput is measured by how frequently a team is able to deploy code and how quickly it can move from committing code to deploying it.
Change failure rate and Mean Time to Recover (MTTR) correspond to systems stability. Stability is measured by how quickly a system can recover from downtime and how many changes succeed versus how many fail.
15.3.5. Cloud financial management¶
Cloud financial management includes four key areas.
To enable cost transparency you must have the right tagging scheme and apply it to all areas of spending. User-defined tags allow customers to label their resources so they can manage them. At a minimum, from cost perspective, customers should use the following 5 tags:
- What cost center does it belong to? This may belong to more then one.
- What application or workload does it support?
- Who owns it?
- What is the expiration date? When should it be turned off? This helps with Reverved Instance purchasing.
- Automation tags can state directions such as “shut me down on the weekend” for and non-production environment, or “This instance runs non-critical workloads and can be freed up for disaster recovery in case of a mulfunction on a different Availability Zone.”
An ideal tool for measuring and monitoring should provide:
- Cost and usage data.
- Optimization recommendations.
- Other information that helps teams make data-driven, cost-based decisions.
AWS Cost Explorer is a free tool that helps customers dive deeper into cost and usage data to indetify trends, pinpoint cost drivers, and detect anomalies.
AWs has identified 4 key pillars of cost optimization best practices:
15.3.5.1. Righ-sizing instances¶
This means selecting the least expensive instance available that meets the functional and performance requirements. Right-sizing is the process of reviewing depoyed resources and seeking opportunities to downsize when possible. For example, if only CPU and RAM are underused, a customer can switch to a smaller size instance.
AWS Cost Explorer generates EC2 instance rightsizing recommendations by scanning your past usage over the previous 14 days. From there, AWS removes Spot Instance usage and any instances it believes that you terminated. AWS then analyzes the remaining instance uage to identify idle and underutilized instances:
- Idle instances are instances that have lower than 1% maximum CPU utilization.
- Underutilized instances are instances with maximum CPU utilization between 1% and 40%.
When AWS Cost Explorer identifies an idle instance, it will generate a termination recommendation. When it identifies an underutilized instance, AWS simulates covering that uasge with a smaller instance within the same family.
15.3.5.2. Increasing application elasticity¶
15.3.5.2.1. Turn off non-production instances¶
In regards to increasing application elasticity for cost optimization, reviewing production versus non-production instances is key. Instances that are non-production, sucas dev, test, and QA, may not need to run during nonworking hours, such as nights and weekends. In these cases, these servers can be shut down, and will stop incurring charges if they are not Reserved Instances. Typically when a nonproduction instance has a usage percentage less than or equal to 36%, it is less expensive to use On-Demand pricing versus Reserved Instances.
A customer can create an AWS Lambda function that can automate the starting and stopping of instances based on parameters like idling and time of day:
How do I stop and start Amazon EC2 instances at regular intervals using Lambda?
15.3.5.2.2. Automatic scaling¶
Automatic scaling helps to ensure the correct number of instances are available to handle the workload of an application. Both the minimum and maximum number of instances can be specified, and automatic scaling ensures that you never go below or above the thresholds.
This provides the customer the opportunity to provision and pay for a baseline and then automatically scale for peak when demand spikes, which lowers costs with no performance impact.
Automatic scaling can be scheduled based on predefined times or performance. Recently, with the introduction of predective scaling for EC2, AWS will use data collected from your actual EC2 usage and billions of data points drwan from AWS’ own observations, in combination with well-trained machine learning models to predict expected traffic ( and EC2 usage) including daily and weekly patterns. The prediction process produces a scaling plan that can drive one or more groups of auto scaled EC2 instances. This allows you to automate the process of proactively scaling, ahead of daily and weekly peaks, improving overall user experience for your site or business, and avoid over-provisioning, which will reduce your EC2 costs.
15.3.5.2.3. Choosing the right pricing model¶
See section Pricing options
15.3.5.2.4. Optimizing storage¶
See section Object Storage Classes