8. Elasticity, High Availability, and Monitoring¶
8.1. Understanding the basics¶
Fault tolerance refers to the ability of a system to remain operational even if some components of that system fail. It can be seen as the built-in redundancy of an application’s components. The user does not suffer any impact from a fault, the SLA is met.
High availability is a concept regarding the entire system. It goes to ensure that:
- Systems are generally functioning and accessible, but it may perform in a degraded state.
- Downtime is minimized as much as possible.
- Minimal human intervention is required.
- Minimal upfront financial investment
A comparison of High Availability on premises versus AWS would be the following:
- Usually, on premises could be very expensive and only applied to mission-critical applications.
- On AWS you have the options to expand availability and recoverability among whatever services you choose.
8.1.1. High Availability¶
The HA service tools are the following:
Elastic Load Balancers. It distributes incoming traffic (loads) among your instances. It can send metrics to Amazon CloudWatch. ELB can be a trigger to notify high latency or if your services are becoming over-utilized. It can also be customize, for example you can configure it to recognize unhealthy EC2 instances. It can be public or internal-facing and it can use multiple different protocols.
Elastic IP addresses. They are useful in providing greater fault tolerance for your application. They are static IP addresses designed for dynamic cloud computing. It allows you to mask a failure of an instance of software by allowing your users to utilize the same IP addresses with replacement resources. Your users continue to access applications even if an instance fails.
Amazon Route 53. It is an authoritative DNS service that it used to translate domain names into IP addresses. It supports:
- Simple routing
- Latency-based routing
- Health checks
- DNS failovers
- Geo-location routing
Auto Scaling launches or terminates instances based on specific conditions. It is designed to assist you building a flexible system that can adjust or modify capacity depending on changes on customer demand. You can create new resources on demand or have scheduled provisioning. This is used to keep your applications and systems running no matter the load is. We can identify 3 types of autoscaling services:
Amazon EC2 Auto Scaling helps you ensure that you have the correct number of Amazon EC2 instances available to handle the load for your application.
Application Auto Scaling allows you to configure automatic scaling for the following resources:
- Amazon ECS services
- Spot Fleet requests
- Amazon EMR clusters
- AppStream 2.0 fleets
- DynamoDB tables and global secondary indexes
- Aurora replicas
- Amazon SageMaker endpoint variants
- Custom resources provided by your own applications or services. For more information, see the GitHub repository.
- Amazon Comprehend document classification endpoints
- Lambda function provisioned concurrency
AWS Auto Scaling which allows you to scale a number of services at the same time and in a very simple fashion. For example, if you have an application that is using EC2 instances and DynamoDB tables, you can setup the automatic provisioning and scaling of all these resources from one single interface.
Amazon CloudWatch is a distributed statistics gathering system. It collects and tracks your metrics of your AWS infrastructure. You can create and use your own custom metrics. If there are metrics that surpasse a threshold CloudWatch in conjunction with Auto Scaling can scale automatically to ensure HA of your architecture.
8.1.2. Fault tolerance¶
The fault tolerant service tools are the following:
- Amazon Simple Queue Service (SQS) which can be used as the backbone of your fault tolerant application. It is a highly reliable distributed messaging system. It helps you to ensure that the queue is always available.
- Amazon Simple Storage Service (S3) which provides highly durable and fault tolerant data storage. It stores the data redundantly across multiple different devices, across multiple facilities in a region.
- Amazon Relational Database Service (RDS) which is web service tool for you to set up, operate and scale relational databases. It provides HA and fault tolerance by offering several features to enhance the realibility on your critical databases. Some of these features include automatic backups, snapshots, and multi-AZ deployments.
8.2. AWS management tools¶
AWS management tools can be classified in 4 main categories with tools that all integrated and interoperable:
- Provisioning and entitlement: AWS CloudFormation, AWS Service Catalog.
- Configuration management: AWS OpsWorks.
- Monitoring: Amazon CloudWatch, AWS Cost Explorer.
- Operations and compliance management: AWS CloudTrail, AWS Config, AWS Systems Manager.
8.2.1. AWS Cost Explorer¶
Cost Explorer helps you visualize and manage your AWS costs and usages over time. It offers a set of reports you can view data with for up to the last 13 months, forecast how much you’re likely to spend for the next 3 months, and get recommendations for what Reserved Instances to purchase. You use Cost Explorer to identify areas that need further inquiry and see trends to understand your costs.
8.2.2. Amazon CloudWatch¶
Amazon CloudWatch is a monitoring service that allows you to monitor your AWS resources and the applications you run on AWS in real time.
Using Amazon CloudWatch alarm actions, you can create alarms that automatically stop, terminate, reboot, or recover your EC2 instances. You can use the stop or terminate actions to help you save money when you no longer need an instance to be running. You can use the reboot and recover actions to automatically reboot those instances or recover them onto new hardware if a system impairment occurs.
8.2.2.1. Metrics¶
Metrics are data about the performance of your systems. By default, several services provide free metrics for resources (such as Amazon EC2 instances, Amazon EBS volumes, and Amazon RDS DB instances). You can also enable detailed monitoring for some resources, such as your Amazon EC2 instances, or publish your own application metrics. Amazon CloudWatch can load all the metrics in your account (both AWS resource metrics and application metrics that you provide) for search, graphing, and alarms. Metric data is kept for 15 months, enabling you to view both up-to-the-minute data and historical data.
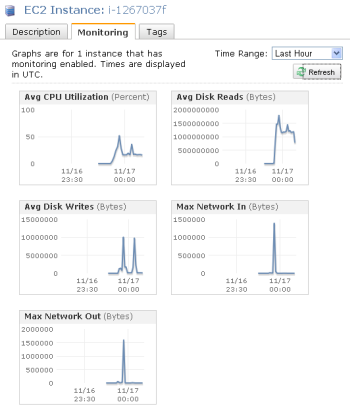
Some Amazon CloudWatch features include collecting and tracking metrics like CPU utilization, data transfer, as well as disk I/O and utilization. We can also monitor services for cloud resources and applications via collecting and monitoring log files. Additionally, you have the ability to set alarms on any of your metrics so that you can send notifications or take other automated actions.
CloudWatch has available Amazon EC2 Metrics for you to use for monitoring:
- CPU Utilization identifies the processing power required to run an application upon a selected instance.
- Disk Read operations metric mesures the completed read operations from all instance store volumes available to the instance in a specified period of time.
- Disrk Write operations metric mesures the completed write operations to all instance store volumes available to the instance in a specified period of time.
- Disk Read bytes metric is used to determine the volume of the data the application reads from the hard disk of the instance. This can be used to determine the speed of the application.
- Disk write bytes metric is used to determine the volume of the data the application writes onto the hard disk of the instance. This can be used to determine the speed of the application.
- Network In measures the number of bytes received on all network interfaces by the instance. This metric identifies the volume of incoming network traffic to a single instance.
- Network Out measures the number of bytes sent out on all network interfaces by the instance. This metric identifies the volume of outgoing network traffic from a single instance.
- Network Packets In measures the number of packets received on all network interfaces by the instance. This metric identifies the volume of incoming traffic in terms of the number of packets on a single instance. This metric is available for basic monitoring only.
- Network Packets Out measures the number of packets sent out on all network interfaces by the instance. This metric identifies the volume of outgoing traffic in terms of the number of packets on a single instance. This metric is available for basic monitoring only.
- Metadata No Token measures the number of times the instance metadata service was accessed using a method that does not use a token.
Sample Auto Scaling group
However, there are certain metrics that are not readily available in CloudWatch such as memory utilization, disk space utilization, and many others which can be collected by setting up a custom metric. You need to prepare a custom metric using CloudWatch Monitoring Scripts which is written in Perl. You can also install CloudWatch Agent to collect more system-level metrics from Amazon EC2 instances. Here’s the list of custom metrics that you can set up:
- Memory utilization
- Disk swap utilization
- Disk space utilization
- Page file utilization
- Log collection
Take note that there is a multi-platform CloudWatch agent which can be installed on both Linux and Windows-based instances. You can use a single agent to collect both system metrics and log files from Amazon EC2 instances and on-premises servers. This agent supports both Windows Server and Linux and enables you to select the metrics to be collected, including sub-resource metrics such as per-CPU core. It is recommended that you use the new agent instead of the older monitoring scripts to collect metrics and logs.
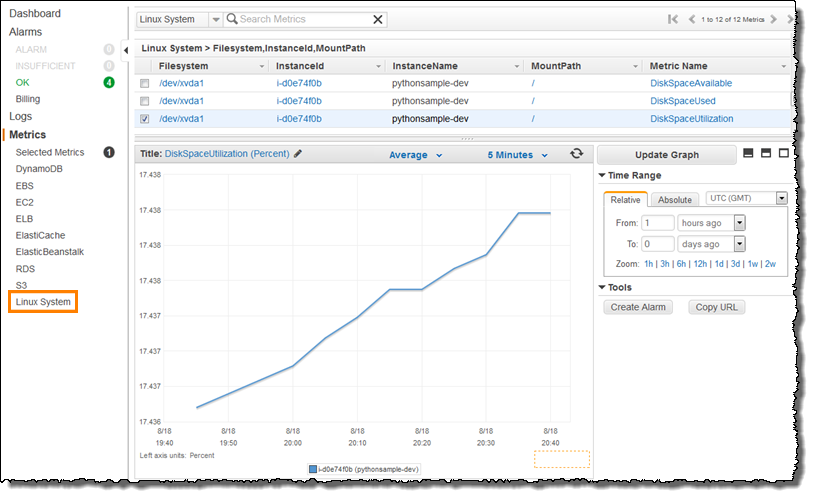
CloudWatch agent to collect both system metrics and log files
Collect Metrics and Logs from Amazon EC2 instances with the CloudWatch Agent
8.2.2.2. CloudWatch Logs¶
CloudWatch Logs agent provides an automated way to send log data to CloudWatch Logs from Amazon EC2 instances. The CloudWatch Logs agent is comprised of the following components:
- A plug-in to the AWS CLI that pushes log data to CloudWatch Logs.
- A script (daemon) that initiates the process to push data to CloudWatch Logs.
- A cron job that ensures that the daemon is always running.
AWS re:Invent 2018: CloudWatch Logs Insights Customer Use Case
8.2.3. AWS CloudTrail¶
AWS CloudTrail is a service which enables compliance, governance, operational auditing and risk auditing in your accounts. It enables to track public activity across teams, accounts, and organizations in one place, in a consistent format. It allows you to explore public activity using a single set of tools, and respond to activity in minutes.
8.2.3.1. Use cases¶
- Simplify compliance workflows. Keep track of API usage in a single location, simplifying audit and compliance processes.
- Enhance security analysis. Perform security analysis and detecting user behavior patterns across services, users, and accounts.
- Monitor data exfiltration risks. Stay alert to data exfiltration risks by collecting activity data on Amazon S3 objects through object-level API events.
- Perform operational troubleshooting. Simplify root cause analysis using CloudTrail events, to reduce time to resolution.
8.2.3.2. AWS CloudTrail events¶
An event in CloudTrail is the record of a single invocation of an AWS REST API and contains not only the name of the event but a lot of information related with this API invocation. This activity can be an action taken by a user, role, or service that is monitorable by CloudTrail. CloudTrail events provide a history of both API and non-API account activity made through the AWS Management Console, AWS SDKs, command line tools, and other AWS services. It is integrated with over 130 AWS services. It automatically gathers usage activity. It records event details, such as operation, principal, request and response attributes, the time it was made, etc. It delivers events to central locations.
There are two types of events that can be logged in CloudTrail: management events and data events. Both of them can be categorized as a read event or a write event, where read events are generally more frequent than write events. By default, trails log management events, but not data events.
Management events are resource control actions, such as update and delete actions on an Amazon EC2 instance. They are generally infrequent compared to data events. It is available from nearly all services.
Data events are fine-grained actions, such as reading from an object in Amazon S3. They can be very high frequency events.
The events are deliver to Amazon S3, and optionally, to Amazon CloudWatch logs. The central collection can be across accounts and regions if desired. The delivery takes typically less 15 minutes at 99th percentile, and some services have delivery times of less than 5 minutes at 99th percentile.
8.2.3.3. Configuring trails¶
A trail is a resource which turns on event capture and delivery. It includes a set of event filters to define which events you are interested in, and defines a set of delivery destinations to select where you want the events stored. It can be set up through AWS Managment console, AWS API, or AWS CLI and you can define more than one trail.
A trail can be applied to all regions or a single region. As a best practice, create a trail that applies to all regions in the AWS partition in which you are working. This is the default setting when you create a trail in the CloudTrail console.
For most services, events are recorded in the region where the action occurred. For global services such as AWS Identity and Access Management (IAM), AWS STS, Amazon CloudFront, and Route 53, events are delivered to any trail that includes global services, and are logged as occurring in US East (N. Virginia) Region.
8.2.3.4. Setting up your event logs¶
By default, CloudTrail event log files are encrypted using Amazon S3 server-side encryption (SSE). You can also choose to encrypt your log files with an AWS Key Management Service (AWS KMS) key. You can store your log files in your bucket for as long as you want. You can also define Amazon S3 lifecycle rules to archive or delete log files automatically. If you want notifications about log file delivery and validation, you can set up Amazon SNS notifications.
AWS re:Invent 2018: Augmenting Security & Improving Operational Health w/ AWS CloudTrail (SEC323)
8.3. Amazon EC2 Auto Scaling¶
Auto Scaling helps you ensure that you have the correct number of Amazon EC2 instances available to handle the load for your application. Using Auto Scaling removes the guesswork of how many EC2 instances you need at a point in time to meet your workload requirements.
When you run your applications on EC2 instances, it is critical to monitoring the performance of your workload using Amazon CloudWatch (for example, CPU utilization). EC2 resources requirements can vary over time, with periods with more demand and others with less demand. Auto Scaling allows you adjust capacity as needed (i.e. Capacity Management) based on conditions that you define and it is especially powerful in environments with fluctuating performance requirements. It allows you to maintain performance and minimize costs. Auto Scaling really answers 2 critical questions:
- How can I ensure that my workload has enough EC2 resources to meet fluctuating performance requirements?
- How can I automate EC2 resource provisioning to occur on-demand?
It matches several reliability design principles: Scale horizontally, Stop guessing capacity and Manage change in automation. If Auto Scaling adds more instances, this is termed as scaling out. When Auto Scaling terminates instances, this is scaling in.
There are 3 components required for auto-scaling:
- Create a launch configuration or launch template determines what will be launched by Auto Scaling, i.e. the EC2 instance characteristics you need to specify: AMI, instance type, security groups, SSH keys, AWS IAM instance profile and user data to apply to the instance.
A launch template is similar to a launch configuration, in that it specifies instance configuration information. Included are the ID of the Amazon Machine Image (AMI), the instance type, a key pair, security groups, and the other parameters that you use to launch EC2 instances. However, defining a launch template instead of a launch configuration allows you to have multiple versions of a template. With versioning, you can create a subset of the full set of parameters and then reuse it to create other templates or template versions. For example, you can create a default template that defines common configuration parameters such as tags or network configurations, and allow the other parameters to be specified as part of another version of the same template.
We recommend that you use launch templates instead of launch configurations to ensure that you can use the latest features of Amazon EC2, such as T2 Unlimited instances.
- Create a Auto Scaling group. It is a logical group of instances for your service and defines where the deployment takes place and some boundaries for the deployment. You define which VPC to deploy the instances, in which load balancer to interact with, and specify the boundaries for a group: the minimum, the maximum, ans the desired size of the Auto Scaling Group. If you set a minimum of 1, if the number of servers goes below 1, another instance will be launched. If you set a maximum of 4, you will never have more than 4 instances in your group. The desire capacity is the number of instances that should be running at any given time (for example 2). The Auto Scaling is going to launch instances or terminate instances in order to meet the desired capacity. You can select the health check type.
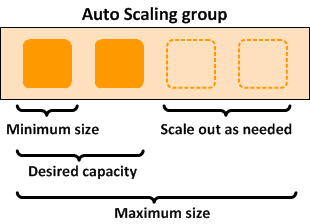
Sample Auto Scaling group
There is a Health Check Grace Period setting (in seconds) in the Auto Scaling group configuration. This indicates how long Auto Scaling should wait until it starts using the ELB health check (which, in turn, has settings for how often to check and how many checks are required to mark an instance as Healthy/Unhealthy).
- Define a least one Auto Scaling policy, which specifies how and when to scale in or scale out, that is, to launch or terminate EC2 instances.
If you are using Auto Scaling and you want to new instances, they must meet the following criteria:
- The instance is in the running state.
- The AMI used to launch the instance must still exist.
- The instance is not a member of another Auto Scaling group.
- The instance is launched into one of the Availability Zones defined in your Auto Scaling group.
- If the Auto Scaling group has an attached load balancer, the instance and the load balancer must both be in EC2-Classic or the same VPC. If the Auto Scaling group has an attached target group, the instance and the load balancer must both be in the same VPC.
8.3.1. Auto Scaling policies¶
There 4 possible types of auto scaling policies: manual scaling, scheduled scaling, dynamic scaling, predictive scaling.
8.3.1.1. Manual Scaling¶
At any time, you can change the size of an existing Auto Scaling group manually.

Manual Scaling
8.3.1.2. Scheduled scaling¶
Scaling based on a schedule allows you to set your own scaling schedule for predictable load changes. For example, every week the traffic to your web application starts to increase on Wednesday, remains high on Thursday, and starts to decrease on Friday. You can plan your scaling actions based on the predictable traffic patterns of your web application. Scaling actions are performed automatically as a function of time and date.
To configure your Auto Scaling group to scale based on a schedule, you create a scheduled action. The scheduled action tells Amazon EC2 Auto Scaling to perform a scaling action at specified times. To create a scheduled scaling action, you specify the start time when the scaling action should take effect, and the new minimum, maximum, and desired sizes for the scaling action. At the specified time, Amazon EC2 Auto Scaling updates the group with the values for minimum, maximum, and desired size specified by the scaling action. You can create scheduled actions for scaling one time only or for scaling on a recurring schedule.
Note
For scaling based on predictable load changes, you can also use the predictive scaling feature of AWS Auto Scaling.
8.3.1.3. Dynamic scaling¶
When you configure dynamic scaling, you must define how to scale in response to changing demand and require you to create CloudWatch alarms for the scaling policies. You create conditions that define high and low thresholds for the alarms to trigger adding or removing instances. Condition-based policies make your Auto Scaling dynamic and able to meet fluctuating requirements. It is best practice to create at least one Auto Scaling policy to specify when to scale out and at least one policy to specify to scale in. You can attach one or more Auto Scaling policies to an Auto Scaling group. It supports the following types of scaling policies: target tracking scaling, simple scaling, and step scaling.
If you are scaling based on a utilization metric that increases or decreases proportionally to the number of instances in an Auto Scaling group, we recommend that you use target tracking scaling policies. Otherwise, we recommend that you use step scaling policies.
For an advanced scaling configuration, your Auto Scaling group can have more than one scaling policy. For example, you can define one or more target tracking scaling policies, one or more step scaling policies, or both. This provides greater flexibility to cover multiple scenarios.
When there are multiple policies in force at the same time, there’s a chance that each policy could instruct the Auto Scaling group to scale out (or in) at the same time. When these situations occur, Amazon EC2 Auto Scaling chooses the policy that provides the largest capacity for both scale out and scale in.
The approach of giving precedence to the policy that provides the largest capacity applies even when the policies use different criteria for scaling in. For example, if one policy terminates three instances, another policy decreases the number of instances by 25 percent, and the group has eight instances at the time of scale in, Amazon EC2 Auto Scaling gives precedence to the policy that provides the largest number of instances for the group. This results in the Auto Scaling group terminating two instances (25 percent of 8 = 2). The intention is to prevent Amazon EC2 Auto Scaling from removing too many instances.
8.3.1.3.1. Target tracking scaling¶
Increase or decrease the current capacity of the group based on a target value for a specific metric. This is similar to the way that your thermostat maintains the temperature of your home: you select a temperature and the thermostat does the rest.
For example, you have a web application that currently runs on two instances and you want the CPU utilization of the Auto Scaling group to stay at around 50 percent when the load on the application changes. This gives you extra capacity to handle traffic spikes without maintaining an excessive amount of idle resources. You can configure your Auto Scaling group to scale automatically to meet this need.
Dynamic Scaling with target tracking
One common configuration to have dynamic Auto Scaling is to create CloudWatch alarms based on performance information from your EC2 instances or a load balancer. When a performance threshold is breached, a CloudWatch alarm triggers an Auto Scaling event which either scales out or scales in EC2 instances in the environment.
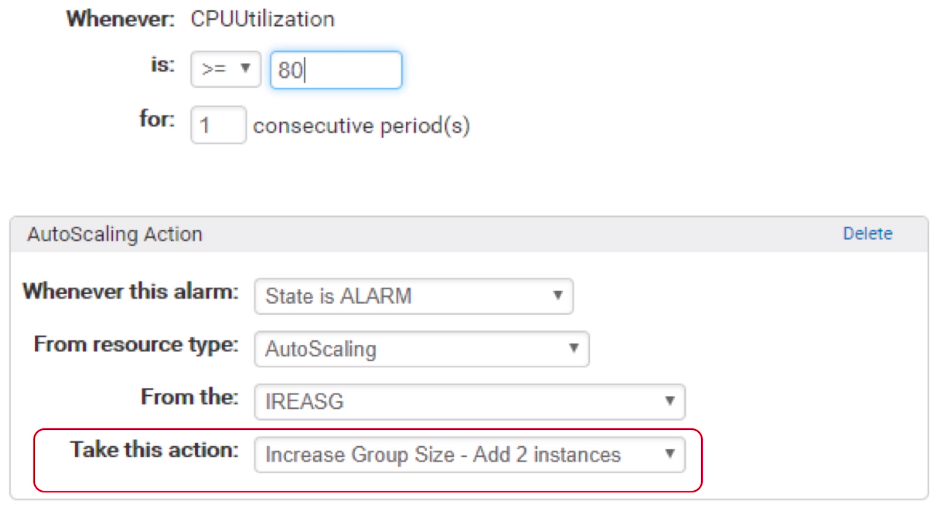
Sample CloudWatch alarm
CloudWatch can monitor metrics such as CPU, network traffic and queue size. CloudWatch has a feature called CloudWatch Logs that allows you pick up logs from EC2 instances, AWS Lambdas or CloudTrail. You can store the logs in the CloudWatch logs. You can also convert logs into metrics by extracting metrics using patterns. CloudWatch provides default metric across many AWS services and resources. You can also define custom metrics for your applications.
8.3.1.3.2. Simple scaling¶
Increase or decrease the current capacity of the group based on a single scaling adjustment. With simple scaling, after a scaling activity is started, the policy must wait for the scaling activity or health check replacement to complete and the cooldown period to expire before responding to additional alarms. Cooldown periods help to prevent the initiation of additional scaling activities before the effects of previous activities are visible.
The cooldown period helps to ensure that your Auto Scaling group doesn’t launch or terminate additional instances before the previous scaling activity takes effect. You can configure the length of time based on your instance warmup period or other application needs. The default is 300 seconds. This gives newly launched instances time to start handling application traffic. After the cooldown period expires, any suspended scaling actions resume. If the CloudWatch alarm fires again, the Auto Scaling group launches another instance, and the cooldown period takes effect again. However, if the additional instance was enough to bring the performance back down, the group remains at its current size.
8.3.1.3.3. Step scaling¶
With step scaling, you choose scaling metrics and threshold values for the CloudWatch alarms that trigger the scaling process as well as define how your scalable target should be scaled when a threshold is in breach for a specified number of evaluation periods. Step scaling policies increase or decrease the current capacity of a scalable target based on a set of scaling adjustments, known as step adjustments. The adjustments vary based on the size of the alarm breach. After a scaling activity is started, the policy continues to respond to additional alarms, even while a scaling activity is in progress. Therefore, all alarms that are breached are evaluated by Application Auto Scaling as it receives the alarm messages.
When you configure dynamic scaling, you must define how to scale in response to changing demand. For example, you have a web application that currently runs on two instances and you want the CPU utilization of the Auto Scaling group to stay at around 50 percent when the load on the application changes. This gives you extra capacity to handle traffic spikes without maintaining an excessive amount of idle resources. You can configure your Auto Scaling group to scale automatically to meet this need. The policy type determines how the scaling action is performed.
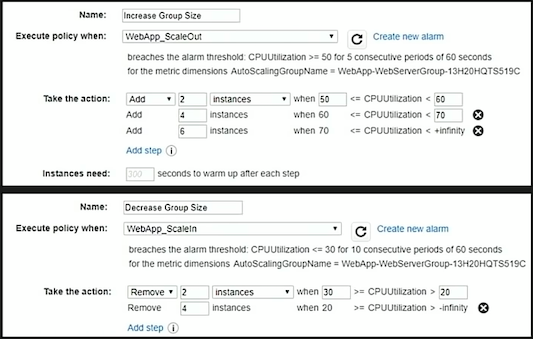
Dynamic Scaling with step scaling
8.3.1.4. Predictive scaling¶
Using data collected from your actual EC2 usage and further informed by billions of data points drawn from Amazon.com observations, we use well-trained Machine Learning models to predict your expected traffic (and EC2 usage) including daily and weekly patterns. The model needs at least one day’s of historical data to start making predictions; it is re-evaluated every 24 hours to create a forecast for the next 48 hours.
It performs a regression analysis between load metric and scaling metric and schedules scaling actions for the next 2 days, hourly, and repeats this process every day.
8.3.2. Termination policies¶
Using termination policies, you can control which instances you prefer to terminate first when a scale-in event occurs. It also describes how to enable instance scale-in protection to prevent specific instances from being terminated during automatic scale in.
Note
Auto Scaling groups with different types of purchase options are a unique situation. Amazon EC2 Auto Scaling first identifies which of the two types (Spot or On-Demand) should be terminated. If you balance your instances across Availability Zones, it chooses the Availability Zone with the most instances of that type to maintain balance. Then, it applies the default or customized termination policy.
8.3.2.1. Default Termination Policy¶
The default termination policy is designed to help ensure that your instances span Availability Zones evenly for high availability. The default policy is kept generic and flexible to cover a range of scenarios. The default termination policy behavior is as follows:
Determine which Availability Zones have the most instances, and at least one instance that is not protected from scale in.
Determine which instances to terminate so as to align the remaining instances to the allocation strategy for the On-Demand or Spot Instance that is terminating. This only applies to an Auto Scaling group that specifies allocation strategies.
For example, after your instances launch, you change the priority order of your preferred instance types. When a scale-in event occurs, Amazon EC2 Auto Scaling tries to gradually shift the On-Demand Instances away from instance types that are lower priority.
Determine whether any of the instances use the oldest launch template or configuration:
3.1. [For Auto Scaling groups that use a launch template]
Determine whether any of the instances use the oldest launch template unless there are instances that use a launch configuration. Amazon EC2 Auto Scaling terminates instances that use a launch configuration before instances that use a launch template.
3.2. [For Auto Scaling groups that use a launch configuration]
Determine whether any of the instances use the oldest launch configuration.
After applying all of the above criteria, if there are multiple unprotected instances to terminate, determine which instances are closest to the next billing hour. If there are multiple unprotected instances closest to the next billing hour, terminate one of these instances at random.
Note that terminating the instance closest to the next billing hour helps you maximize the use of your instances that have an hourly charge. Alternatively, if your Auto Scaling group uses Amazon Linux or Ubuntu, your EC2 usage is billed in one-second increments.
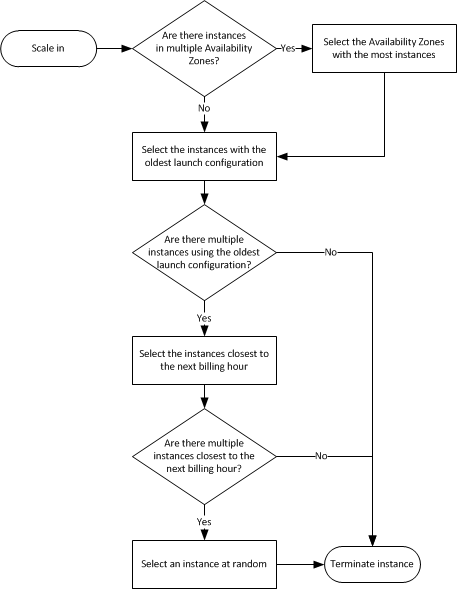
Default termination policy flowchart
8.3.2.2. Customizing the Termination Policy¶
You have the option of replacing the default policy with a customized one to support common use cases like keeping instances that have the current version of your application.
When you customize the termination policy, if one Availability Zone has more instances than the other Availability Zones that are used by the group, your termination policy is applied to the instances from the imbalanced Availability Zone. If the Availability Zones used by the group are balanced, the termination policy is applied across all of the Availability Zones for the group.
Amazon EC2 Auto Scaling supports the following custom termination policies:
OldestInstance. Terminate the oldest instance in the group. This option is useful when you’re upgrading the instances in the Auto Scaling group to a new EC2 instance type. You can gradually replace instances of the old type with instances of the new type.NewestInstance. Terminate the newest instance in the group. This policy is useful when you’re testing a new launch configuration but don’t want to keep it in production.OldestLaunchConfiguration. Terminate instances that have the oldest launch configuration. This policy is useful when you’re updating a group and phasing out the instances from a previous configuration.ClosestToNextInstanceHour. Terminate instances that are closest to the next billing hour. This policy helps you maximize the use of your instances that have an hourly charge.Default. Terminate instances according to the default termination policy. This policy is useful when you have more than one scaling policy for the group.OldestLaunchTemplate. Terminate instances that have the oldest launch template. With this policy, instances that use the noncurrent launch template are terminated first, followed by instances that use the oldest version of the current launch template. This policy is useful when you’re updating a group and phasing out the instances from a previous configuration.AllocationStrategy. Terminate instances in the Auto Scaling group to align the remaining instances to the allocation strategy for the type of instance that is terminating (either a Spot Instance or an On-Demand Instance). This policy is useful when your preferred instance types have changed. If the Spot allocation strategy is lowest-price, you can gradually rebalance the distribution of Spot Instances across your N lowest priced Spot pools. If the Spot allocation strategy is capacity-optimized, you can gradually rebalance the distribution of Spot Instances across Spot pools where there is more available Spot capacity. You can also gradually replace On-Demand Instances of a lower priority type with On-Demand Instances of a higher priority type.
8.3.2.3. Instance Scale-In Protection¶
To control whether an Auto Scaling group can terminate a particular instance when scaling in, use instance scale-in protection. You can enable the instance scale-in protection setting on an Auto Scaling group or on an individual Auto Scaling instance. When the Auto Scaling group launches an instance, it inherits the instance scale-in protection setting of the Auto Scaling group. You can change the instance scale-in protection setting for an Auto Scaling group or an Auto Scaling instance at any time.
Instance scale-in protection starts when the instance state is InService. If you detach an instance that is protected from termination, its instance scale-in protection setting is lost. When you attach the instance to the group again, it inherits the current instance scale-in protection setting of the group.
If all instances in an Auto Scaling group are protected from termination during scale in, and a scale-in event occurs, its desired capacity is decremented. However, the Auto Scaling group can’t terminate the required number of instances until their instance protection settings are disabled.
Instance scale-in protection does not protect Auto Scaling instances from the following:
- Manual termination through the Amazon EC2 console, the
terminate-instancescommand, or theTerminateInstancesaction. To protect Auto Scaling instances from manual termination, enable Amazon EC2 termination protection. - Health check replacement if the instance fails health checks. To prevent Amazon EC2 Auto Scaling from terminating unhealthy instances, suspend the
ReplaceUnhealthyprocess. - Spot Instance interruptions. A Spot Instance is terminated when capacity is no longer available or the Spot price exceeds your maximum price.
8.3.3. Use cases¶
8.3.3.1. Automate provisioning of instances¶
One of the use cases of Auto Scaling is automating the provision of EC2 instances. When the instances come up, they need to have some software and applications installed. You have to approaches to achieve it:
- You can use AMIs with all required configuration and software for this purpose, this is called the golden image. This golden image can be specified in the launch template.
- You can define a base AMI and install code and configuration as needed through user data in the launch template, AWS CodeDeploy, AWS Systems Manager, or even with configuration tools such as Puppet, Chef, and Ansible.
#!/bin/bash
# Install updates
sudo yum update -y;
# Install AWS CodeDeploy agent
cd /home/ec2-user;
wget https://aws-codedeploy-us-east-1.s3.region-identifier.amazonaws.com/latest/install \ -o install &&
chmod +x ./install &&
sudo ./install auto && sudo service codedeploy-agent start;
8.3.3.1.1. Perform additional actions with lifecycle hooks¶
Another use case is when the EC2 instance comes up, you want to execute additional actions when the instance is in pending state or terminating state such as:
- Assign EC2 IP address or ENI on launch.
- Register new instances with DNS, external monitoring systems, firewalls.
- Load existing state from Amazon S3 or other system.
- Pull down log files before instance is terminated.
- Investigate issues with an instance before terminating it.
- Persist instance state to external system.
The EC2 instances in an Auto Scaling group have a path, or lifecycle, that differs from that of other EC2 instances. The lifecycle starts when the Auto Scaling group launches an instance and puts it into service. The lifecycle ends when you terminate the instance, or the Auto Scaling group takes the instance out of service and terminates it. The following illustration shows the transitions between instance states in the Amazon EC2 Auto Scaling lifecycle.
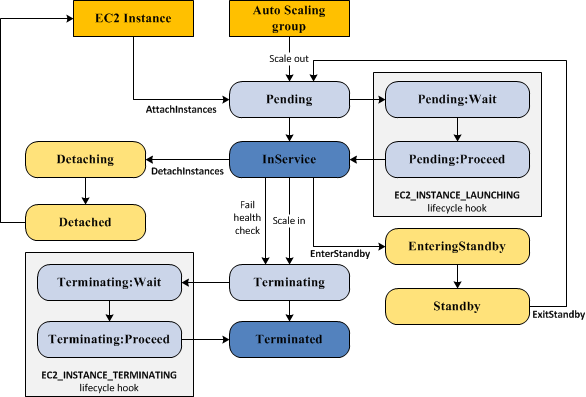
Auto Scaling Lifecycle
Note
You are billed for instances as soon as they are launched, including the time that they are not yet in service.
You can receive notification when state transitions happen. You can rely on notifications to react to changes that happened. It is available via Amazon SNS and Amazon CloudWatch Events.
8.3.3.1.2. Register instances behind load balancer¶
You have full integration with ELB allowing you to automatically register instances behind Application Load Balancer, Network Load Balancer, and Classic Load Balancer.
8.3.3.2. Reduce paging frequency¶
8.3.3.2.1. Replace unhealthy instances¶
When the load balancer determines that an instance is unhealthy, it stops routing requests to that instance. The load balancer resumes routing requests to the instance when it has been restored to a healthy state. There are 3 ways of checking the status of your EC2 instances:
- Via the Auto Scaling group. The default health checks for an Auto Scaling group are EC2 status checks only. If an instance state is different from
runningor system health check equalsimpaired, the Auto Scaling group considers the instance unhealthy and replaces it. If you attached one or more load balancers or target groups to your Auto Scaling group, the group does not, by default, consider an instance unhealthy and replace it if it fails the load balancer health checks. - Via the ELB health checks. However, you can optionally configure the Auto Scaling group to use Elastic Load Balancing health checks. This ensures that the group can determine an instance’s health based on additional tests provided by the load balancer. The load balancer periodically sends pings, attempts connections, or sends requests to test the EC2 instances. These tests are called health checks. Load balancer health checks fail if ELB health equals
OutOfService.
If you configure the Auto Scaling group to use Elastic Load Balancing health checks, it considers the instance unhealthy if it fails either the EC2 status checks or the load balancer health checks. If you attach multiple load balancers to an Auto Scaling group, all of them must report that the instance is healthy in order for it to consider the instance healthy. If one load balancer reports an instance as unhealthy, the Auto Scaling group replaces the instance, even if other load balancers report it as healthy.
- Via custom health checks. You can manually mark instances as
unhealthy. You can integrate with external monitoring systems.
Why did Auto Scaling Group terminate my healthy instance(s)?
8.3.3.2.2. Balance capacity across AZs¶
The nodes for your load balancer distribute requests from clients to registered targets. When cross-zone load balancing is enabled, each load balancer node distributes traffic across the registered targets in all enabled Availability Zones. When cross-zone load balancing is disabled, each load balancer node distributes traffic only across the registered targets in its Availability Zone.
With Application Load Balancers, cross-zone load balancing is always enabled. With Network Load Balancers, cross-zone load balancing is disabled by default. When you create a Classic Load Balancer, the default for cross-zone load balancing depends on how you create the load balancer. With the API or CLI, cross-zone load balancing is disabled by default. With the AWS Management Console, the option to enable cross-zone load balancing is selected by default.
For example, suppose we have 6 EC2 instances across 2 AZs behind an Elastic Load Balancer. In this case, we will have 3 EC2 instances in each AZ. If one of the AZs goes down, then Auto Scaling is going to terminate the 3 EC2 instances that were in this AZ and launch 3 EC2 instances in the AZ that is alive. Whenever the failed AZ is restored, then Auto Scaling rebalance the number of EC2 instances and setting 3 EC2 instances in each AZ.
8.3.3.3. Use spot instances to reduce costs¶
You can reduce costs, optimize performance and eliminate operational overhead by automatically scaling instances across instance families and purchasing models (spot, on-demand, and reserved instances) in a single Auto Scaling group.
You can specify what percentage of your group capacity should be fulfilled by on-demand instances, and spot instances to optimize cost. Use a prioritized list for on-demand instance types to scale capacity during an urgent, unpredictable event to optimize performance.
AWS re:Invent 2015: All You Need To Know About Auto Scaling (CMP201)
AWS re:Invent 2018: Capacity Management Made Easy with Amazon EC2 Auto Scaling (CMP377)