12. Microservices and serverless architectures¶
12.1. Amazon ECS¶
Amazon ECS enables you to inject sensitive data into your containers by storing your sensitive data in either AWS Secrets Manager secrets or AWS Systems Manager Parameter Store parameters and then referencing them in your container definition. This feature is supported by tasks using both the EC2 and Fargate launch types. Secrets can be exposed to a container in the following ways:
- To inject sensitive data into your containers as environment variables, use the
secretscontainer definition parameter. - To reference sensitive information in the log configuration of a container, use the
secretOptionscontainer definition parameter.

AWS Lambda
Within your container definition, specify secrets with the name of the environment variable to set in the container and the full ARN of either the Secrets Manager secret or Systems Manager Parameter Store parameter containing the sensitive data to present to the container. The parameter that you reference can be from a different Region than the container using it, but must be from within the same account.
12.2. AWS Lambda¶
There are 4 main principles that allows us to identify if a service is serverless or not:
- There are no servers to provision or manage.
- It scales with usage.
- You pay for value. You don’t need to pay for the time the resource is idle.
- It has availability and fault tolerance built in. In AWS, serverless take advantage of the availability and fault tolerance given by AWS global infrastructure.
AWS Lambda
AWS Lambda handles load balacing, auto scaling, failures, security isolation, OS management, … for you.
Serverless applications have 3 components: the event source, that triggers the AWS Lambda function, which calls some services.
- Event sources can be changes in changes in data state, requests to endpoints, changes in resource state.
- Functions that can be developed in Node.js, Python, Java, C#, Go, Ruby, Runtime API.
A Lambda function consists of code and any associated dependencies. In addition, a Lambda function also has configuration information associated with it. Initially, you specify the configuration information when you create a Lambda function. Lambda provides an API for you to update some of the configuration data. The anatomy of a Lambda function is as follows:
- Handler() function is the function to be executed upon invocation.
- Event object is data sent during Lambda function invocation.
- Context object are the methods available to interactwith runtime information (equest ID,log group, more).
AWS Lambda runtime API and layers are features that allow developers to share, discover, and deploy both libraries and languages as part of their serverless applications. Runtime API enables developers to use Lambda with any programming language. Layers let functions easily share code. Upload layer once, reference within any function. Layers promote separation of responsibilities, lets developers focus on writing business logic. Combined, runtime API and layers allow developers to share any programming language or language version with others.
There are 3 types of Lambda execution models:
- Synchronous (push). For instance, an Amazon API Gateway request to AWS Lambda functions and expect some response.
- Asynchronous (event). For instance, a Amazon SNS invocates AWS Lambda function and it makes some task on it without sending nothing to the client.
- Poll-based. For instance, Amazon DynamoDB Streams or Amazon Kinesis streams are continously poll and Lambda makes an invocation for you.
The Lambda permission model allows you to establish fine-grained security controls for both execution and invocation:
- Execution policies. They define what AWS resources/API calls can this function access via IAM and is used in streaming invocations. For instance: Lambda function A can read from DynamoDB table users.
- Function policies are used for sync and async invocations. For example: Actions on bucket X can invoke Lambda function Z.
Introduction to AWS Lambda & Serverless Applications
Building APIs with Amazon API Gateway
12.2.1. Environment Variables¶
When you create or update Lambda functions that use environment variables, AWS Lambda encrypts them using the AWS Key Management Service. When your Lambda function is invoked, those values are decrypted and made available to the Lambda code.

AWS Lambda Environment Variables
Lambda encrypts environment variables with a key that it creates in your account (an AWS managed customer master key). Use of this key is free. You can also choose to provide your own key for Lambda to use instead of the default key.
However, if you wish to use encryption helpers and use KMS to encrypt environment variables after your Lambda function is created, you must create your own AWS KMS key and choose it instead of the default key. The default key will give errors when chosen. Creating your own key gives you more flexibility, including the ability to create, rotate, disable, and define access controls, and to audit the encryption keys used to protect your data.
When you provide the key, only users in your account with access to the key can view or manage environment variables on the function. Your organization may also have internal or external requirements to manage keys used for encryption and control when they are rotated.
You can also encrypt environment variable values client-side before sending them to Lambda, and decrypt them in your function code. This obscures secret values in the Lambda console and API output, even for users who have permission to use the key. In your code, you retrieve the encrypted value from the environment and decrypt it by using the AWS KMS API.
12.2.1.1. Networking¶
You can configure a function to connect to a virtual private cloud (VPC) in your account. Use Amazon Virtual Private Cloud (Amazon VPC) to create a private network for resources such as databases, cache instances, or internal services. Connect your function to the VPC to access private resources during execution.
AWS Lambda runs your function code securely within a VPC by default. However, to enable your Lambda function to access resources inside your private VPC, you must provide additional VPC-specific configuration information that includes VPC subnet IDs and security group IDs. AWS Lambda uses this information to set up elastic network interfaces (ENIs) that enable your function to connect securely to other resources within your private VPC.
Lambda functions cannot connect directly to a VPC with dedicated instance tenancy. To connect to resources in a dedicated VPC, peer it to a second VPC with default tenancy.
Your Lambda function automatically scales based on the number of events it processes. If your Lambda function accesses a VPC, you must make sure that your VPC has sufficient ENI capacity to support the scale requirements of your Lambda function. It is also recommended that you specify at least one subnet in each Availability Zone in your Lambda function configuration.
By specifying subnets in each of the Availability Zones, your Lambda function can run in another Availability Zone if one goes down or runs out of IP addresses. If your VPC does not have sufficient ENIs or subnet IPs, your Lambda function will not scale as requests increase, and you will see an increase in invocation errors with EC2 error types like EC2ThrottledException. For asynchronous invocation, if you see an increase in errors without corresponding CloudWatch Logs, invoke the Lambda function synchronously in the console to get the error responses.
12.2.1.2. Monitoring¶
AWS Lambda automatically monitors functions on your behalf, reporting metrics through Amazon CloudWatch. These metrics include total invocation requests, latency, and error rates. The throttles, Dead Letter Queues errors and Iterator age for stream-based invocations are also monitored.
You can monitor metrics for Lambda and view logs by using the Lambda console, the CloudWatch console, the AWS CLI, or the CloudWatch API.

AWS Lambda metrics functions list
12.2.1.3. Pricing¶
You buy compute time in 100ms increments. There is no hourly, daily, or monthly minimums and no per-device fees. You never pay for idle time. The free tier covers 1 million requests and 400,000 GBs of compute every month, every customer.
Lambda exposes only a memory control, with the percentage of CPU core and network capacity allocated to a function proportionally. If your code is CPU, network or memory-bound, then it could be cheaper to choose more memory.
You pay for the AWS resources that are used to run your Lambda function. To prevent your Lambda function from running indefinitely, you specify a timeout. When the specified timeout is reached, AWS Lambda terminates execution of your Lambda function. It is recommended that you set this value based on your expected execution time. The default timeout is 3 seconds and the maximum execution duration per request in AWS Lambda is 900 seconds, which is equivalent to 15 minutes.
12.2.1.4. Limits¶
By default, the AWS Lambda limits the total concurrent executions across all functions within a given region to 1000. By setting a concurrency limit on a function, Lambda guarantees that allocation will be applied specifically to that function, regardless of the amount of traffic processing the remaining functions. If that limit is exceeded, the function will be throttled but not terminated.
12.3. AWS Step Functions¶
AWS Step Functions provides serverless orchestration for modern applications. Orchestration centrally manages a workflow by breaking it into multiple steps, adding flow logic, and tracking the inputs and outputs between the steps. As your applications execute, Step Functions maintains application state, tracking exactly which workflow step your application is in, and stores an event log of data that is passed between application components. That means that if networks fail or components hang, your application can pick up right where it left off.
Application development is faster and more intuitive with Step Functions, because you can define and manage the workflow of your application independently from its business logic. Making changes to one does not affect the other. You can easily update and modify workflows in one place, without having to struggle with managing, monitoring and maintaining multiple point-to-point integrations. Step Functions frees your functions and containers from excess code, so your applications are faster to write, more resilient, and easier to maintain.
12.4. Amazon API Gateway¶
Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. With a few clicks in the AWS Management Console, you can create an API that acts as a ?front door? for applications to access data, business logic, or functionality from your back-end services, such as workloads running on Amazon Elastic Compute Cloud (Amazon EC2), code running on AWS Lambda, or any web application. Since it can use AWS Lambda, you can run your APIs without servers.
Amazon API Gateway creates a unified API frontend for multiple microservices. It provides DDos protection and throttling for your backend. It allows you to authenticate and authorize requests to a backend. It can throttle, meter and monitize API usage by third-party developers.
Amazon API Gateway handles all the tasks involved in accepting and processing up to hundreds of thousands of concurrent API calls, including traffic management, authorization and access control, monitoring, and API version management. Amazon API Gateway has no minimum fees or startup costs. You pay only for the API calls you receive and the amount of data transferred out.
Amazon API Gateway provides throttling at multiple levels including global and by service call. Throttling limits can be set for standard rates and bursts. For example, API owners can set a rate limit of 1,000 requests per second for a specific method in their REST APIs, and also configure Amazon API Gateway to handle a burst of 2,000 requests per second for a few seconds. Amazon API Gateway tracks the number of requests per second. Any request over the limit will receive a 429 HTTP response. The client SDKs generated by Amazon API Gateway retry calls automatically when met with this response.
You can add caching to API calls by provisioning an Amazon API Gateway cache and specifying its size in gigabytes. The cache is provisioned for a specific stage of your APIs. This improves performance and reduces the traffic sent to your back end. Cache settings allow you to control the way the cache key is built and the time-to-live (TTL) of the data stored for each method. Amazon API Gateway also exposes management APIs that help you invalidate the cache for each stage.

Amazon API Gateway settings
All of the APIs created with Amazon API Gateway expose HTTPS endpoints only. Amazon API Gateway does not support unencrypted (HTTP) endpoints. By default, Amazon API Gateway assigns an internal domain to the API that automatically uses the Amazon API Gateway certificate. When configuring your APIs to run under a custom domain name, you can provide your own certificate for the domain.
12.5. AWS X-Ray¶
You can use AWS X-Ray to trace and analyze user requests as they travel through your Amazon API Gateway APIs to the underlying services. API Gateway supports AWS X-Ray tracing for all API Gateway endpoint types: regional, edge-optimized, and private. You can use AWS X-Ray with Amazon API Gateway in all regions where X-Ray is available.
X-Ray gives you an end-to-end view of an entire request, so you can analyze latencies in your APIs and their backend services. You can use an X-Ray service map to view the latency of an entire request and that of the downstream services that are integrated with X-Ray. And you can configure sampling rules to tell X-Ray which requests to record, at what sampling rates, according to criteria that you specify. If you call an API Gateway API from a service that’s already being traced, API Gateway passes the trace through, even if X-Ray tracing is not enabled on the API.
You can enable X-Ray for an API stage by using the API Gateway management console, or by using the API Gateway API or CLI.
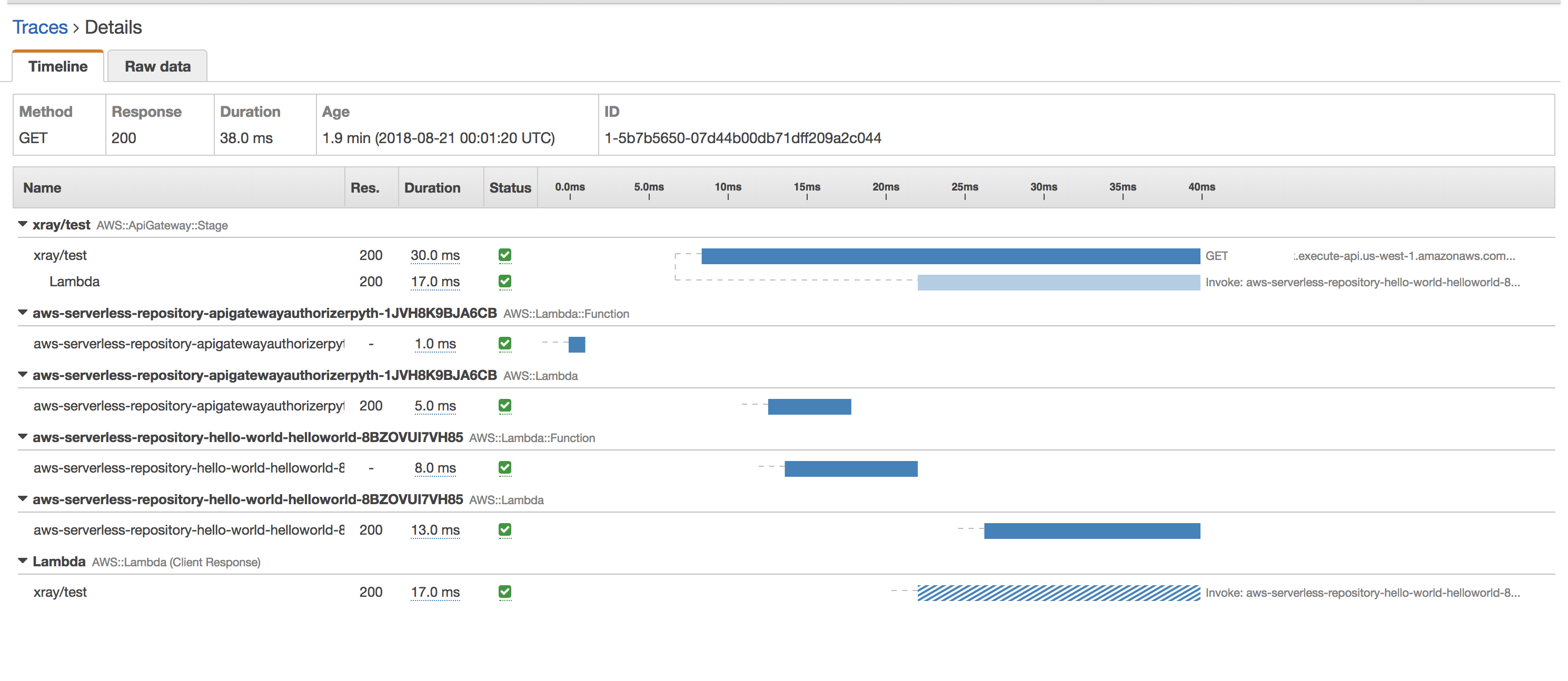
Amazon API Gateway trace view with AWS X-Ray
12.6. Amazon ECS¶
In Amazon EC2 container service, Docker is the only container platform supported by EC2 container service presently.