11. Building decoupled architectures¶
11.1. Asynchronous messaging¶
If loose-coupling is important, especially in a system that requires high resilience and has unpredictable scale, another option is asynchronous messaging. Asynchronous messaging is a fundamental approach for integrating independent systems, or building up a set of loosely coupled systems that can operate, scale, and evolve independently and flexibly. As Tim Bray said, “If your application is cloud-native, or large-scale, or distributed, and doesn’t include a messaging component, that’s probably a bug.”
When you have a monolithic application, all the communication among the different components occur internally. When you decouple the application into a microservices architecture, the communication among them can be done by messaging solutions.
In the messaging process we have several actors: the producers, the message, and the consumers. When sending messages is up to the producers and the consumers to define what the format and the contents are. You can also send attributes along with your messages, that are key/values pairs that you want to attach to your messages. This attributes can have a business meanings (for instance: CustomerId=1234, MessageType=NewBooking) or technical meaning (for instance: SourceHost=ec2-203-0-113-25.compute-1.amazonaws.com, ProgramName=WebServer-PID:9989). The payload can be encrypted but the attributes cannot. The attributes can be used to filter messages.
The AWS messaging services can be classified in terms of the use:
- Modern application development, which are ideal for born-in-the-cloud apps. They have simple APIs and offer unlimited throuhput. We have Amazon SQS for dealing queues, Amazon SNS for subscribing to topics, Amazon Kinesis for dealing streams.
- App migration, which are API-compatible, feature-rich and use standard protocols. We have Amazon MQ as a message broker.
AWS re:Invent 2018: Choosing the Right Messaging Service for Your Distributed App (API305)
11.2. Amazon SQS¶
11.2.1. Basic Amazon SQS Architecture¶
11.2.1.1. Distributed Queues¶
There are three main parts in a distributed messaging system: the components of your distributed system, your queue (distributed on Amazon SQS servers), and the messages in the queue.
In the following scenario, your system has several producers (components that send messages to the queue) and consumers (components that receive messages from the queue). The queue (which holds messages A through E) redundantly stores the messages across multiple Amazon SQS servers.

11.2.1.2. Message Lifecycle¶
The following scenario describes the lifecycle of an Amazon SQS message in a queue, from creation to deletion.
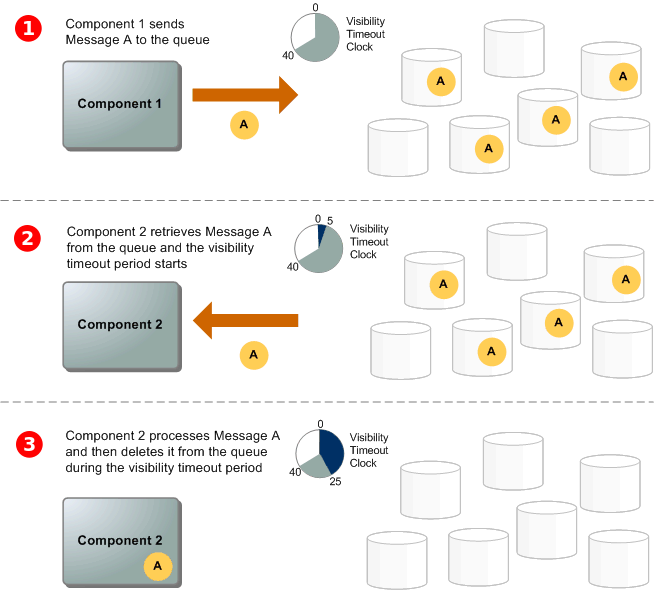
- A producer (component 1) sends message A to a queue, and the message is distributed across the Amazon SQS servers redundantly.
- When a consumer (component 2) is ready to process messages, it consumes messages from the queue, and message A is returned. While message A is being processed, it remains in the queue and isn’t returned to subsequent receive requests for the duration of the visibility timeout.
- The consumer (component 2) deletes message A from the queue to prevent the message from being received and processed again when the visibility timeout expires.
Note
Amazon SQS automatically deletes messages that have been in a queue for more than maximum message retention period. The default message retention period is 4 days. However, you can set the message retention period to a value from 60 seconds to 1,209,600 seconds (14 days) using the SetQueueAttributes action. Once the message retention limit is reached, your messages are automatically deleted.
Amazon SQS uses short polling by default, querying only a subset of the servers (based on a weighted random distribution) to determine whether any messages are available for inclusion in the response. Short polling works for scenarios that require higher throughput. However, you can also configure the queue to use Long polling instead, to reduce cost.
The ReceiveMessageWaitTimeSeconds is the queue attribute that determines whether you are using Short or Long polling. By default, its value is zero which means it is using Short polling. If it is set to a value greater than zero, then it is Long polling. Quick facts about SQS Long Polling:
- Long polling helps reduce your cost of using Amazon SQS by reducing the number of empty responses when there are no messages available to return in reply to a ReceiveMessage request sent to an Amazon SQS queue and eliminating false empty responses when messages are available in the queue but aren’t included in the response.
- Long polling reduces the number of empty responses by allowing Amazon SQS to wait until a message is available in the queue before sending a response. Unless the connection times out, the response to the
ReceiveMessagerequest contains at least one of the available messages, up to the maximum number of messages specified in theReceiveMessageaction. - Long polling eliminates false empty responses by querying all (rather than a limited number) of the servers. Long polling returns messages as soon any message becomes available.
Amazon SQS supports dead-letter queues, which other queues (source queues) can target for messages that can’t be processed (consumed) successfully. Dead-letter queues are useful for debugging your application or messaging system because they let you isolate problematic messages to determine why their processing doesn’t succeed.
11.2.2. Amazon SQS Standard Queues¶
Amazon SQS offers standard as the default queue type. Standard queues support a nearly unlimited number of transactions per second (TPS) per API action (SendMessage, ReceiveMessage, or DeleteMessage). Standard queues support at-least-once message delivery. However, occasionally (because of the highly distributed architecture that allows nearly unlimited throughput), more than one copy of a message might be delivered out of order. Standard queues provide best-effort ordering which ensures that messages are generally delivered in the same order as they’re sent.
You can get duplicate messages for instance in this scenario:
- A producer sends a message to the queue.
- The queue stores the message durably.
- There is a networking problem when the producer was calling send message.
- The producer gets a timeout. It doesn’t know if SQS got the message or it didn’t.
- The producer retry the sent.
- SQS standard will store a duplicate of the message.
When you want to consume messages, the only thing you want to do is to call receive message and provide the queue URL. You do not have to tell SQS which message you want to receive, it is the responsibility of SQS to select the best message to give to you.
When the consumer gets the receive message, the SQS get the message and gives it to the consumer. The consumer can start working on it, but notice that the message is still in the queue. It is not immediately removed, it is invisible, and you can control the invibility timeout. This invisibility timeout makes sure that if another consumer wants to fetch another message, SQS won’t give you this particular message because some consumer is already working on it.
When the consumer successfully consumes the message, call the delete message on the message that it got, which actually achieves the removal of the message. Only when the consumer acknowledges that it successfully consumed the message, the message is removed from the queue. This guarantees that the message is consumed at least once.
When the consumer has a problem consuming the message, the easiest solution for the consumer is just forget about the message and do nothing. What happen next is that the invisibility timeout on the message it was working on expires, and the message is available for consumption again.
11.2.2.1. Amazon SQS Visibility Timeout¶
When a consumer receives and processes a message from a queue, the message remains in the queue. Amazon SQS doesn’t automatically delete the message. Because Amazon SQS is a distributed system, there’s no guarantee that the consumer actually receives the message (for example, due to a connectivity issue, or due to an issue in the consumer application). Thus, the consumer must delete the message from the queue after receiving and processing it.

Immediately after a message is received, it remains in the queue. To prevent other consumers from processing the message again, Amazon SQS sets a visibility timeout, a period of time during which Amazon SQS prevents other consumers from receiving and processing the message. The default visibility timeout for a message is 30 seconds. The minimum is 0 seconds. The maximum is 12 hours.
11.2.2.2. Message Ordering¶
A standard queue makes a best effort to preserve the order of messages, but more than one copy of a message might be delivered out of order. If your system requires that order be preserved, we recommend using a FIFO (First-In-First-Out) queue or adding sequencing information in each message so you can reorder the messages when they’re received.
11.2.2.3. At-Least-Once Delivery¶
Amazon SQS stores copies of your messages on multiple servers for redundancy and high availability. On rare occasions, one of the servers that stores a copy of a message might be unavailable when you receive or delete a message.
If this occurs, the copy of the message isn’t deleted on that unavailable server, and you might get that message copy again when you receive messages. Design your applications to be idempotent (they should not be affected adversely when processing the same message more than once).
11.2.3. Amazon SQS FIFO (First-In-First-Out) Queues¶
FIFO queues have all the capabilities of the standard queue. FIFO (First-In-First-Out) queues are designed to enhance messaging between applications when the order of operations and events is critical, or where duplicates can’t be tolerated. FIFO queues also provide exactly-once processing but have a limited number of transactions per second (TPS):
- By default, with batching, FIFO queues support up to 3,000 messages per second (TPS), per API action (
SendMessage,ReceiveMessage, orDeleteMessage). To request a quota increase, submit a support request. - Without batching, FIFO queues support up to 300 messages per second, per API action (
SendMessage,ReceiveMessage, orDeleteMessage).
Note
Amazon SNS isn’t currently compatible with FIFO queues.
The name of a FIFO queue must end with the .fifo suffix. The suffix counts towards the 80-character queue name quota. To determine whether a queue is FIFO, you can check whether the queue name ends with the suffix.
Typically what you need is to process messages in sequence for specific subgroup of messages, such as Customer ID, but you can work with multiple customers in parallel. To send the message to the FIFO queue, the producer must to tell what the message group for which the message belongs to. It is just a tag that you put in the message and it is not necessary to pre-create this group. There is no limitation of the number of messages that you can send.
Image an scenario where:
- A producer sends a message to the queue.
- The queue stores the message durably.
- There is a networking problem when the producer was calling send message.
- The producer gets a timeout. It doesn’t know if SQS got the message or it didn’t.
- The producer retry the sent.
- SQS keeps track of the identifiers of the messages sent to it in the last 5 minutes, even if they are already consumed. As a consequence, it is able to detect that it is retry of sending the same message and no duplicate is introduced in the queue. An OK is returned to the producer, because the message is already present.
When the consumer calls receive and FIFO decides the group you are are going to get messages. The SQS get the message and gives it to the consumer. The consumer can start working on it, but notice that the message is still in the queue. It is not immediately removed, it is invisible, and you can control the invibility timeout. The difference with standard queues is that no other consumer can receive messages from the same group as selected for this message. This is how it is preserved the order of the messages within the group. The entire group is lock until the consumer finishes processing the message.
When the consumer successfully consumes the message, call the delete message on the message that it got, which actually achieves the removal of the message. Only when the consumer acknowledges that it successfully consumed the message, the message is removed from it group within the queue. This guarantees that the message is consumed only once. The group is unlocked and another messages from this group can be consumed for the same or another consumer. You cannot guarantee which consumer is going to get the next message, there is no consumer affinity.
When the consumer has a problem consuming the message, the easiest solution for the consumer is just forget about the message and do nothing. What happen next is that the invisibility timeout on the message it was working on expires, and the group is available for consumption again.
11.2.4. Limits¶
A single Amazon SQS message queue can contain an unlimited number of messages. However, there is a 120,000 limit for the number of inflight messages for a standard queue and 20,000 for a FIFO queue. Messages are inflight after they have been received from the queue by a consuming component, but have not yet been deleted from the queue.
11.3. Amazon SNS¶
The most important characteristics of SNS are the following:
- It is a flexible, fully managed pub/sub messaging and mobile communications service.
- It coordinates the delivery of messages to subscribing endpoints and clients, therefore enabling you to send different information to different subscribers.
- It is easy to setup, operate and send realiable communications.
- It allows you to decouple and scale microservices, distributed systems and serverless communications.
Amazon SNS allows you to have pub/sub messaging for different systems in Amazon, like AWS Lambda, HTTP/S and Amazon SQS. Amazon SNS Mobile Notifications allows you to do similar publishing but to different mobile systems, like ADM, APNS, Baidu, GCM, MPNS, and WNS.
11.3.1. Amazon SNS topics¶
The objective of SNS is to send something and deliver it to multiple destinations. It is a pub/sub model in which you publish something and you have multiple subscribers via SNS topics. In this case, we have producers but no consumers.
With a topic, you can publish messages to it or configure subscriptions or destinations you want to deliver messages. The destinations that you can configure are Amazon SQS (except FIFO queue which are not supported yet), AWS Lambda, HTTP/s endpoint, mobile app, SMS, e-mail.
When a producer publish a message, it gets an acknowledge, before even it is delivered to each destination. It means that you will see the same latency of publishing locations whether you have one destination or multiple destinations.
What happens internally in SNS is that a fanout is performed. For each subscribed destination, a copy of the message will be sent. You can configure filters in destinations that prevent to arrive a several destinations. You can interpret this stage as multiple internal queues that you do not see that keeps track of each individual destination. Finally, the copies of the messages are sent to the destinations.
If one of the channels fail for any reason (for instance, it was an HTTP endpoint and the web server was not running), we receive notifications for the successful deliveries and we keep track of the delivery that failed. We will retry the failed message sending, the number of retries depend on the destination. For an SQS queue or an AWS Lambda it will retry a large amount of times and the message will probably be delivered. For HTTP endpoints, you have to define a delivery policy. Each delivery policy is comprised of four phases:
- Immediate Retry Phase (No Delay). This phase occurs immediately after the initial delivery attempt. There is no delay between retries in this phase.
- Pre-Backoff Phase. This phase follows the Immediate Retry Phase. Amazon SNS uses this phase to attempt a set of retries before applying a backoff function. This phase specifies the number of retries and the amount of delay between them.
- Backoff Phase. This phase controls the delay between retries by using the retry-backoff function. This phase sets a minimum delay, a maximum delay, and a retry-backoff function that defines how quickly the delay increases from the minimum to the maximum delay. The backoff function can be arithmetic, exponential, geometric, or linear.
- Post-Backoff Phase. This phase follows the backoff phase. It specifies a number of retries and the amount of delay between them. This is the final phase.
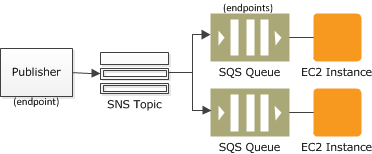
11.3.2. Fanout¶
A “fanout” pattern is when an Amazon SNS message is sent to a topic and then replicated and pushed to multiple Amazon SQS queues, HTTP endpoints, or email addresses. This allows for parallel asynchronous processing. For example, you could develop an application that sends an Amazon SNS message to a topic whenever an order is placed for a product. Then, the Amazon SQS queues that are subscribed to that topic would receive identical notifications for the new order. The Amazon EC2 server instance attached to one of the queues could handle the processing or fulfillment of the order, while the other server instance could be attached to a data warehouse for analysis of all orders received.
When a consumer receives and processes a message from a queue, the message remains in the queue. Amazon SQS doesn’t automatically delete the message. Because Amazon SQS is a distributed system, there’s no guarantee that the consumer actually receives the message (for example, due to a connectivity issue, or due to an issue in the consumer application). Thus, the consumer must delete the message from the queue after receiving and processing it.
Immediately after the message is received, it remains in the queue. To prevent other consumers from processing the message again, Amazon SQS sets a visibility timeout, a period of time during which Amazon SQS prevents other consumers from receiving and processing the message. The default visibility timeout for a message is 30 seconds. The maximum is 12 hours.
11.4. Amazon MQ¶
Amazon MQ is a managed message broker service for Apache ActiveMQ that makes it easy to set up and operate message brokers in the cloud. Connecting your current applications to Amazon MQ is easy because it uses industry-standard APIs and protocols for messaging, including JMS, NMS, AMQP, STOMP, MQTT, and WebSocket. Using standards means that in most cases, there’s no need to rewrite any messaging code when you migrate to AWS.
Amazon MQ, Amazon SQS, and Amazon SNS are messaging services that are suitable for anyone from startups to enterprises. If you’re using messaging with existing applications and want to move your messaging service to the cloud quickly and easily, it is recommended that you consider Amazon MQ. It supports industry-standard APIs and protocols so you can switch from any standards-based message broker to Amazon MQ without rewriting the messaging code in your applications.
If you are building brand new applications in the cloud, then it is highly recommended that you consider Amazon SQS and Amazon SNS. Amazon SQS and SNS are lightweight, fully managed message queue and topic services that scale almost infinitely and provide simple, easy-to-use APIs. You can use Amazon SQS and SNS to decouple and scale microservices, distributed systems, and serverless applications, and improve reliability.
11.5. Amazon Simple Workflow Service (SWF)¶
11.5.1. Introduction¶
It is a managed workflow service that helps developers build, run, and scale applications that coordinate work across distributed components. You can of Amazon SWF as a fully managed state tracker and task coordinator for your background jobs that requires sequential and parallel steps. An application can consists of several different tasks to be performed and a certain sequence driven by a set of conditions. SWF makes it easy to architect and implement and coordinate these tasks in AWS cloud.
When building solutions to coordinate tasks in a distributed environment, the developer has to account for several variables. Tasks that drive a processing steps can be long running and may fail, timeout or require a restart. They often complete with varying throughtputs and latencies. Tracking and visualization tasks in all these cases is not only challenging but also undifferentiated work. As applications and tasks scale up, you see different distributed system problems, for example: you must ensure that a task is assigned once and that the outcome is tracked reliably through unexpected failures and outages.
By using Amazon SWF you can easily manage your application tasks and how to coordinate them.

The tasks in this workflow are sequential. An order must be verified before making a charge in the credit card. A credit card must be charged successfully before an order must be shipped. An order must be shipped before being recorded. Even so, because SWF supports distributed processes, these tasks can be carried out in different locations. If the tasks are programmatic in nature, they can also be written in different programming languages or using different tools.
In addition to sequential processing of tasks, SWF also supports workflow with parallel processing of tasks. Parallel tasks are performed at the same time and may be carried out independently by different applications or human workers. Your workflow makes decissions on how to proceed once one or more parallel tasks have been completed.
The benefits of SWF are:
- Logical separation. The service promotes the separation betwwen the control flow of your background jobs stepwise logic and the actual units of work that contains your unique business logic. This allows you to separately manage, maintain and scale state machinery of your application from the core business logic. As your business requirements change, you can easily change application logic without having to worry about your state machinery, tasks dispatch and flow control.
- Reliable. It runs on Amazon HA data centers so the state tracking and tasks processing engine is available whenever application need them. SWF redundantly stores tasks, realiably dispatches them to application components, track the progress and keeps the related state.
- Simple. It is simple to use and replaces the complexity of customed-coded solution and process automation software with a fully managed cloud web service. This eliminates the need for developers to manage infrastructure plumbing for the process automation so they can focus on the functionality of the application.
- Scale. SWF scales with your application usage. No manual administration of your workflow service is required as you add more workflows to your application or increase the complexity of your workflows.
- Flexible. It allows you write your application components and coordination logic in any programming language and run them in the cloud or on-premises.
11.5.2. Overview¶
Domain is a collection of related workflows. A workflow starter is any application that can initiate workflow executions. Workflows are collections of actions and actions are tasks or workflow steps. Decider implements the workflow coordination logic. Activity workers implements actions. Workflow history is the detailed, complete and consistent record of every event that occur since the workflow execution started. Additionally, in the course of its operations SWF interacts with a number of different types of programmatic actors. Actors can be workflow starters, deciders or activity workers. These actors communicate with SWF through its API. You can develop these actors in any programming language.

Each workflow runs on an AWS resource called the Domain. Domains provide a way of scoping SWF resources within your AWS account. All the components of your workflow such as workflow types and activities types must be specified to be in a domain. It is possible to have more than a workflow in a domain. However, workflows in different domains can interact one with another. When setting up a new workflow, before you set up any of the other workflow components you have to register a domain if you have not done so. When you register a domain you have to specify a workflow history retention period. This period is the length of time SWF would continue to retain information about the workflow execution after the workflow execution is complete.
Workflows coordinate and manage the execution of activities that can be run asynchronously across multiple computing devices and that can feature both sequential and parallel processing. The workflow starter starts the workflow instance, also refered as the workflow execution, and can interact with an instance during execution for purposes such as pass additional data to the workflow worker or obtaining the current workflow state. The workflow starter uses a workflow client to start the workflow execution and interacts with the workflow as needed during execution and handles clean up. The workflow starter can be a locally run application, a web application, the AWS CLI or even the AWS management console.
SWF interacts with activity workers and deciders by providing them with work assigments known as tasks. There are 3 types of tasks in Amazon SWF:
- Activity task tells an activity worker to perform its function, such as to check inventory or charge a credit card. The activity task contains all the information that the activity worker needs to perform its function.
- Lambda task is similar to an activity task but executes the a Lambda function an set up a traditional SWF activity.
- Decision task tells the decider that the state of the workflow execution has changed, so that the decider can determine the next activity that needs to be performed. It contains to current workflow history. SWF schedule the decision task when the workflow starts and whenever the state of a workflow changes, such as when an activity task complete.
Each decision task contains a paginated view of the entire workflow execution history. The decider analyzes the workflow execution history and responds back to SWF with a set of decisions that specify what should occur next in the workflow execution. Essentially, every decision task gives the decider an opportunity to assess the workflow and provides direction back to SWF. To ensure that no conflicting decisions are processed, SWF assigns each decision task to exactly one decider and allows one decision task at a time to be active in a workflow execution.
A decider is an implementation of a workflow coordination logic. Deciders control the flow of activity tasks in a workflow execution. Whenever a change occur in workflows executions, such as the completion of an activity task, SWF creates a decision task that contains the workflow history up to that point in time and assigns the task to a decider. When the decider receives the decision task from the SWF, it analyzes the workflow execution history to determine the next appropriate steps in the workflow execution. The decider communicates these steps back to SWF using decisions. A decision is a SWF data type that can represent next actions.
An activity worker is a process or thread that performs the activity tasks that are part of your workflow. The activity tasks represent one of the tasks that you identified in your application. Each activity worker pulls SWF for new tasks that is appropriate for that activity worker to perform and certain tasks can only be performed by certain activity workers. After receiving a task, the activity worker processes the tasks to completion and reports SWF that the task was completed and provides the result. The activity worker polls then for a new task. The activity worker is associated with a workflow execution continuing this way: processing tasks until the workflow execution itself is complete. Multiple activity workers can process tasks of the same activity type.
Workflow history is a detailed, complete, and consistent record of every event that occurred since the workflow execution started. An event represents a discete change in the workflow execution state, such as a new activity being scheduled or running activity being completed. The workflow history contains every event that causes the execution state of the workflow execution to change, such as scheduled completed activities, tasks timeouts and signals. Operations that don’t change the state of the workflow execution don’t typically appear in the workflow history. For example, the workflow history doesn’t show pull attempts or the use of visibility operations. The Workflow history has a set of key benefits:
- It enables applications to be stateless because all information about a workflow execution is stored in the Workflow history.
- For each worflow execution the Workflow history provides of what activities were scheduled, the current status, and the results. The workflow execution uses this information to determine the next steps.
- The history provides the detailed auditrail that you can use to monitor running workflow executions and verify completed workflow executions.
The process that SWF follows is the following:
- A workflow starter kick outs your workflow execution. For example, this can be a web server front end.
- SWF receives the start workflow execution request and then scheduled a Decision task.
- The decider receives the task from SWF, reviews the history and applies the coordination logic to determine the activity that needs to be performed.
- SWF receives the decision, schedule the activity task and waits the activity task to complete or time out.
- SWF assigns the activity to a worker that performs the tasks and returns the results to SWF.
- SWF receives the results of the activity, add them to the workflow history, and schedule the decision task.
- This process repeats itself for each activity in your workflow.

Deciders and activity workers communicates with SWF using long polling. With this approach, the decider or activity worker periodically initiates communication with SWF notifying SWF of visibility to accept the task and then specify the tasks list to get tasks from. If the task is available in a specified task list, SWF returns it immediately in the response. If no task is available, SWF holds the TCP connection open up to 60 seconds, so that if a task becomes available during that time, it can be returned in the same connection.
11.5.3. Use Cases¶
In general, customers have used SWF to build applications for video encoding, social commerce, infrastructure provisioning, mapreduce pipelines, business process management, and several other use cases.
11.5.4. Other considerations¶
By default, each workflow execution can run for a maximum of 1 year in Amazon SWF. This means that it is possible that in your workflow, there are some tasks which require manual action that renders it idle.
Amazon SWF does not take any special action if a workflow execution is idle for an extended period of time. Idle executions are subject to the timeouts that you configure. For example, if you have set the maximum duration for an execution to be 1 day, then an idle execution will be timed out if it exceeds the 1 day limit. Idle executions are also subject to the Amazon SWF limit on how long an execution can run (1 year).