16. Domains¶
16.1. Domain 1: Design Resilient Architectures¶
16.1.1. 1.1 Choose reliable/resilient storage¶
The reason you want to make sure your storage is resilient is that this way, even in the event of a disaster, you don’t lose data or state.
16.1.1.1. Storage options¶
16.1.1.1.1. EC2 Instance Store¶
This lives on your physical HW where your EC2 compute instance run.
- They are ephemeral volumes. When the instance terminates or stops, they are lost.
- Only certain EC2 instances types have instance stores.
- The size is fixed since this store is on the physical host.
- The disk type whether it is SSD or HDD is also fixed based on the instance type and so it is the capacity. Both of these are a function of the instance type.
- Application-level durability. While your application is running you can rely on the instance store but since it is ephemeral you cannot on much beyond that.
Generally, you want to use the instance store for caching or for storing other temporary data that you are replicating somewhere else. This way you can get the fastest access that the instance store provide and at the same time you are not affected by the ephemeral of the instance store.
16.1.1.1.2. Elastic Block Store¶
This an attachable storage that connects to one EC2 instance at a time.
- Different types
- It supports encryption and snapshots.
- Some EBS volume types support provisioned IOPS, meaning that you can configure the volume for a larger or smaller number of read and writes per second.
- The EBS volume persists beyond the lifecycle than an EC2 instance. You can stop or even terminate a EC2 instance and still preserve the EBS volume.
- You can attach multiple volumes to a single instance. However, you can only attach one instance to a EBS volume at a time. When you have multiple EBS volumes attached to your instance, you can use RAID 0 and striping to achieve higher throughput and IOPS.
Think of EBS volumes as durable, attachable storage for your EC2 instances. These are the 4 types of EBS volumes.

There are 2 primary types of EBS volumes: SSD and HDD and each one has 2 subtypes. SSD volumes have much better IOPS, which is read/write operations per second. This is because SSD are Solid State disks with no moving parts. HDD or Hard Disk Drives have good throughput and gives you lower IOPS.
SSD is good for random access while HDD are great for sequential access. HDD are also cheaper than SSD. HDD are good for sequential access because with this type of access you are going to have large blocks of data to read in and fewer read/write operations. For example, if you are processing log files or Big Data workloads made up of sequences of records, HDD will give great performance at a lower price.
With SSD and HDD, there are 2 subtypes of EBS volumes. General Purpose SSD (gp2) is the cheaper SSD volume, Provisioned IOPS SSD (io1) is more expensive. Provisioned IOPS gives you the ability to scale up the number of reads/writes and gives you a better performance at a higher price. Similarly, for Throughput Optimized HDD (st1) is more expensive and has better specs than Cold HDD (sc1).
16.1.1.1.3. Amazon EFS¶
Introduction to Amazon Elastic File System (EFS)
This is similar to EBS because you mount it as a disk in your EC2 instances.
- It gives you shared file storage in the AWS Cloud. Multiple EC2 instances can access the same EFS volume.
- It gives you petabyte-scale file system
- The capacity is elastic, it scales up and down as you grow or shrink your footprint.
- It supports NFS v4.0 and 4.1 (NFSv4) protocol.
- It is compatible with Linux-based AMIs for Amazon EC2. It is not currently supported for Windows.
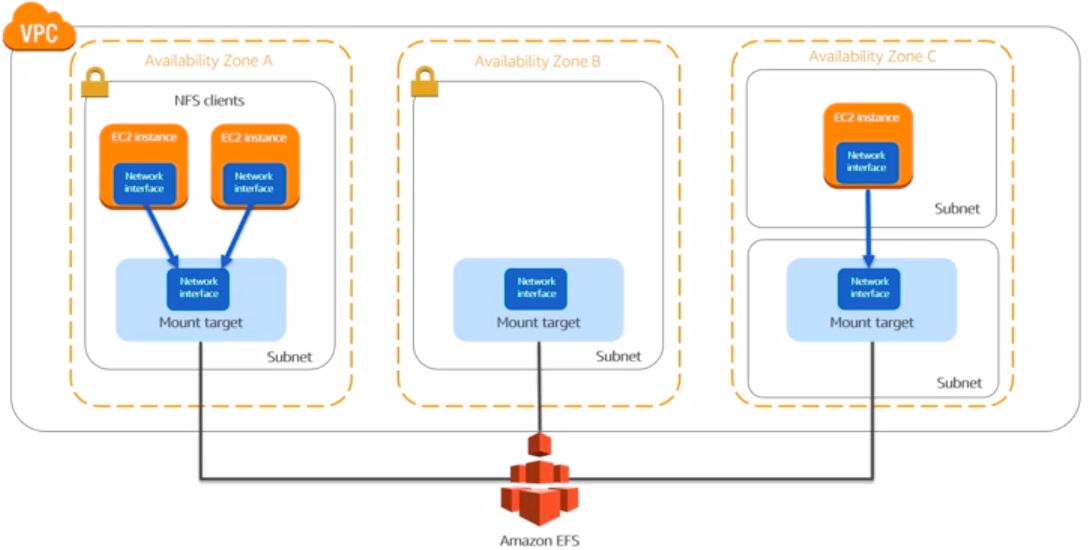
Amazon EFS architecture
You create an EFS volume and then create mount points for it in a particular VPC. The EFS volumen can only attach to a single VPC at a time. Within this VPC, you get mount targets that your EC2 instances can then connect to.
16.1.1.1.4. Amazon S3¶
For object storage, the primary option is S3.
The consistency model. To give you ilimited storage S3 is implemented as a distributed system. With distributed systems the consistency model can be strongly consistent or eventually consistent. S3 gives you strong consistence for new objects and it gives you eventually consistence for updates. Eventually consistence means that if you update an object and you do a read/write afterwards, you may get the previous version of the object. This is because it is a scalable distributed system.
It gives you several storage classes: S3 Standard, S3 Standard-IA. The storage classes offer a tradeoff:
- Standard is cheaper for access, meaning uploads and downloads.
- Standard-IA is cheaper for storage, but more expensive for access.
It offers several options for Server Side Encryption:
- SSE-S3: S3 manages master key used to encrypt files on the server side.
- SSE-KMS: KMS manages master key used to encrypt files on the server side.
- SSE-C: Customer provides and uses master key used to encrypt files on the server side.
It enables encryption of data in transit by supporting uploads and downloads using HTTPS.
It allows you enabling version on a bucket. Previous versions of files remain available even if the file is updated or deleted. This a great way to ensure that your files are protected from accidental deletes or overwrites.
You can control S3 access through IAM user policies, through bucket policies or through ACLs.
It supports multi-part uploads, where you upload a large file in parallel parts.
It has an Internet-accessible API.
It has virtually unlimited capacity.
It is region scoped.
It is designed for 11 nines of durability.
16.1.1.1.5. Amazon Glacier¶
Suppose you have data that you want to hold on for a long period of time. You want to keep them on cold storage so that it always there, but you are not planning to access it very often. This is where Glacier comes in.
It is a solution for data backup and archive storage.
It provides archives which correspond to files and vaults which are a collection of archives.
It has 3 retrieval types: expedited, standard, and bulk. They offer different tradeoffs between latency and cost:
- Bulk is the cheapest but take longer and can take up to 12 hours at this time.
- Expedited is more expensive but faster and can take up to 5 minutes at this time.
It encrypts data by default.
A great way to use Glacier is to set up S3 lifecycle policies on your buckets. This lifecycle policies can move data into Glacier automatically after a period of time. This is great for archiving old data.
It is region scoped.
It is designed for 11 nines of durability.
16.1.2. 1.2 Determine how to design decoupling mechanisms using AWS services¶
16.1.2.1. High Availability¶
Decoupling ensures that if one tier or component fails, the others are not impacted because they are decoupled.

Example of tightly-coupled system
This a tightly-coupled system: The web server takes requests and then sends an email over the email service. When the email service goes down, the web server is forced to become unoperational. The email service going down can be a perfectly normal event: may you bring down the email server to upgrade it to a new version of the email service, or to upgrade the HW or may it can be a failure of the email service. Regardless, the impact of failures is large in tightly coupled systems.

Example of decoupled system
This system has an SQS for holding messages for the email service. The Web server has not to wait for the email service to do its jobs, it queues the work and moves on. This kind of asynchronous interaction is much more resource efficient of the web server side. Furthermore, if the email service goes down, the web server is not impacted, it can continue to function. Not only that: none of the messages are lost, the messages are safely persisted in the SQS queue and it will wait for the email service to come back again. Once the service comes back online, the messages can be processed.
16.1.2.2. Scalability¶
Another benefit from decoupling is scalability. In this system, a web server is calling a logging service. If the web server sends a high volume of requests to the logging service, it can overwhelm it and caused it to become overloaded.

Example of a overloaded system
We can solve this problem by decoupling the web server from the logging server using SQS queue. The logging service can scale out when the volume of requests goes up. When the volume of requests goes down, the logging service can scale down. The scale down is important to keep our costs down when we are not using the extra servers.

Example of a decoupled system preventing from overloading
We can use a load balancer for decoupling. It distributes the incoming requests across the servers running the logging services. The load balancer is useful when the backend service return response is important. If there is no response required by the caller (in this case the web server), a queue can be used instead.
16.1.2.3. Identity of components¶
Suppose we have an external client making requests to web server inside a VPC. The request and the response goes over the public Internet. If the web server goes offline, the client will have an error. If we have some automation implemented so that we replace the web server with another server which is based on the same image. The problem is that the new server has a new IP address assigned by the VPC. This means that the client is not able to it up to the IP is propagated to the client through DNS.
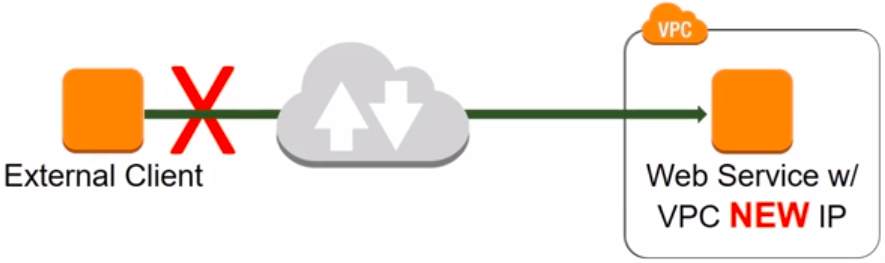
System with the new web server with a different IP
One way to solve this problem is to use an elastic IP address. If the server goes offline, the new instance will use the same Elastic IP address. An Elastic IP address is an IP address that can move from one instance to another. We have decoupled the identity of the server.
16.1.3. 1.3 Determine how to design a multi-tier architecture solution¶
Multi-tier architectures are naturally decoupled. Each tier can scale independently. The entire application may not need to scale when scaling event occurs.
16.1.4. 1.4 Determine how to design high availability and/or fault tolerant architectures¶
When you are operating at scale, in case of an event of failure or an unusual or exceptional event, you want to treated as a normal operational event. You want your application to stay highly available in case of a fault and to continue to keep providing value and service to your users.
16.1.4.1. Fault tolerance¶
The more loose your system is coupled, the more easily it scales and the more fault-tolerant it can be.
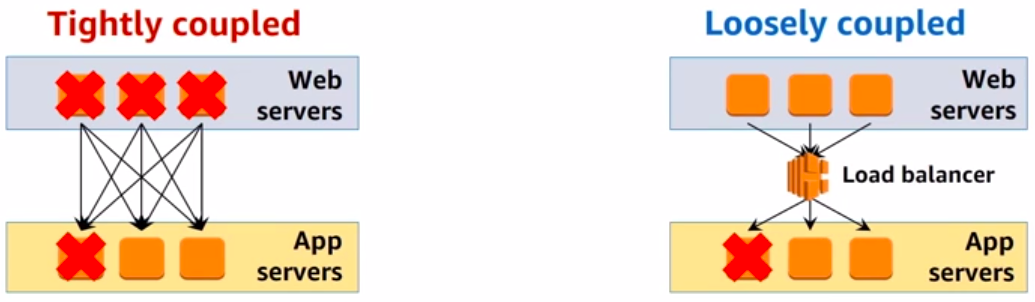
Tightly-coupled systems versus Loosely-coupled systems
16.1.5. Test axioms¶
- Expect “Single AZ” will never be a right answer.
- Using AWS managed services should always be preferred.
- Fault tolerant and HA are not the same thing.
- Expect that everything will fail at some point and design accordingly
16.2. Domain 2: Define Performant Architectures¶
16.2.1. 2.1 Choose performant storage and databases¶
16.2.1.1. Elastic Block Store¶
The EBS volume types offer different tradeoff in performance. SSD are more expensive and offer more perform better in IOPS, meaning random reads and writes. HDD are cheaper and perform better for sequential reads and writes.

EBS volume types performance
Another key to highly performant architectures is to offload all static content to S3 instead of keeping them on the servers. Instead of folders from your webservers for your html, javascript, CSS, images, video files, and any other static content, you want to move all of them to S3. This dramatically improves your webserver performance. It takes load out of the webserver and frees CPU and memory for serving dynamic content.
16.2.1.2. Amazon S3 buckets¶
To upload your data to S3 you need:
- Create a bucket in one of the AWS Regions. The bucket name becomes the subdomain of the S3 object URL.
- Upload any number of objects to the bucket.
S3 objects automatically get a URL assigned to them that is based on the bucket name. You can have a virtual host-based URL or a path-based URL. The virtual host-based URL contains the bucket name as part of the domain name:
http://[bucket name].s3.amazonaws.com
http://[bucket name].s3-aws-region.amazonaws.com
The path-based URL has the bucket name as the bucket as the first part of the path:
http://s3-aws-region.amazonaws.com/[bucket name]/[key]
You can use an URL with the region name or without it, and it will redirect to the region that corresponds. Buckets are always tight to a region, eventhough you can reference them without the region name. Buckets name are globally unique. If a call a bucket “mybucket”, no other bucket in any region can have the same name. The full path after the bucket name is called the key.
16.2.1.3. Lifecycle policies¶
A common pattern with data files is that initially they are hot, there is a lot of interest in processing them, but over time they are not accessed that often, finally there are rarely accessed. However, you need to hold them for some time. This is where lifecycle policies come in. They can move cold data to cheaper storage and the hot data to the more accesible storage.
16.2.1.4. Performant storage on databases¶
We have several options:
Relational Database with Amazon RDS. You should use RDS when:
- You are using joins, complex transactions or complex queries.
- You have a medium-to-high query/write rate.
- Do not scale more than a single worker node/shard.
- High durability.
You should not use RDS (but use DynamoDB) when:
- Massive read/write rates (e.g. 150K writes/second).
- Sharding.
- You use simple GET/PUT requests and queries.
- You need a engine that is not provided by AWS or you want a customized RDBMS.
The RDS master DB can be scaled up by using a bigger instance type for it. The other way to scale RDS is by using read replicas. Read replicas are supported with Aurora, PostgreSQL, MySQL and MariaDB. Using read replicas you can offloads the read requests to the read replicas and take some of the load out of the master DB.
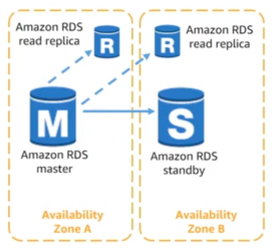
RDS read replicas
Managed NoSQL database with Amazon DynamoDB, adequate for access patterns that match the key-value paradigm. Yo do not specify how much space you need when you create a DynamoDB table. The DynamoDB grows as your data footprint changes. You do specify the throughput (how many reads/writes) you need and DynamoDB scales to allocate resources based on throughput capacity requirements (read/write). The throughput is specified in read capacity units (rcus) and write capacity units (wcus).
Read capacity unit (1 read per second for an item up to 4 KB in size). Each rcu gives you:
- One strongly consistent read per second, meaning that you read something and read it back and you are guaranteed to have the latest value.
- If you willing to relax the strong consistency requirement. You can get two eventually consistent reads per second.
Write capacity unit (1 write for second for an item up to 1 KB in size).
Data Warehouse with Amazon Redshift. Redshift gives you a SQL interface, it is useful if you analytic queries instead of transactional queries. You are not inserting or getting a single row rather you want to compute aggregate numbers across an entire table.
16.2.2. 2.2 Apply caching to improve performance¶
16.2.3. Amazon CloudFront¶
Caching can improve the performance of your application without requiring to redesigning or rewriting the core logic or algorithms. You can cache the data from your application at different levels. You can cache at the web level using a CDN such as CloudFront.
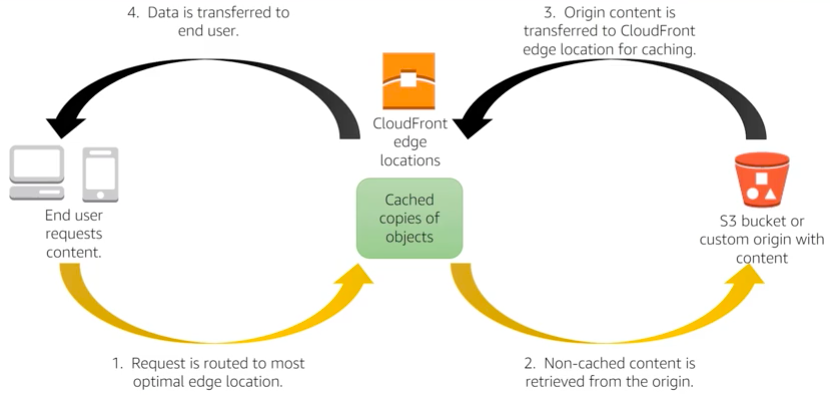
Caching in CloudFront
16.2.4. Amazon ElastiCache¶
You can apply caching at the application and database levels. You can use ElastiCache to cache what you otherwise you repetedly fetch from the DB backend. By using a cache with your DB backend, you can take some of your load out of your databases. Moreover, you can improve the RTT of your queries because you are heading the cache instead of the DB for many of them.

RDS read replicas
ElastiCache gives you 2 different types of caches:
Memcached. It is simpler and easier to setup. It has the following features:
- Multithreading.
- Low maintenance.
- Easy horizontal scalability and auto discovery.
Redis. It is more sophisticated and gives you support for data types. It is more than a simple key-value store.
- Support for data structures.
- Persistence.
- Atomic operations.
- Pub/sub messaging.
- Read replicas/failover.
- Cluster mode/sharded clusters.
16.2.5. 2.3 Design solutions for elasticity and scalability¶
To make your applications perform well regardless of how much traffic they receive, we want to be able to scale them. We want to grow them in response to traffic spikes, this improves performance. At the same time, we want to shrink when the traffic subsides, this helps to keep our costs low. There are 2 types of scaling for your applications:
- Vertical scaling is when change in the specifications of the instances (CPU, memory). If you replace a smaller instance with a larger one, is also called scaling up. If you replace a larger one with a smaller one, then it scales down.
- Horizongal scaling is when you increase o decrease the number of instances (add or remove instances as needed). It is called scaling in and scaling out. The easiest way to do horizontal scaling is through Auto Scaling.
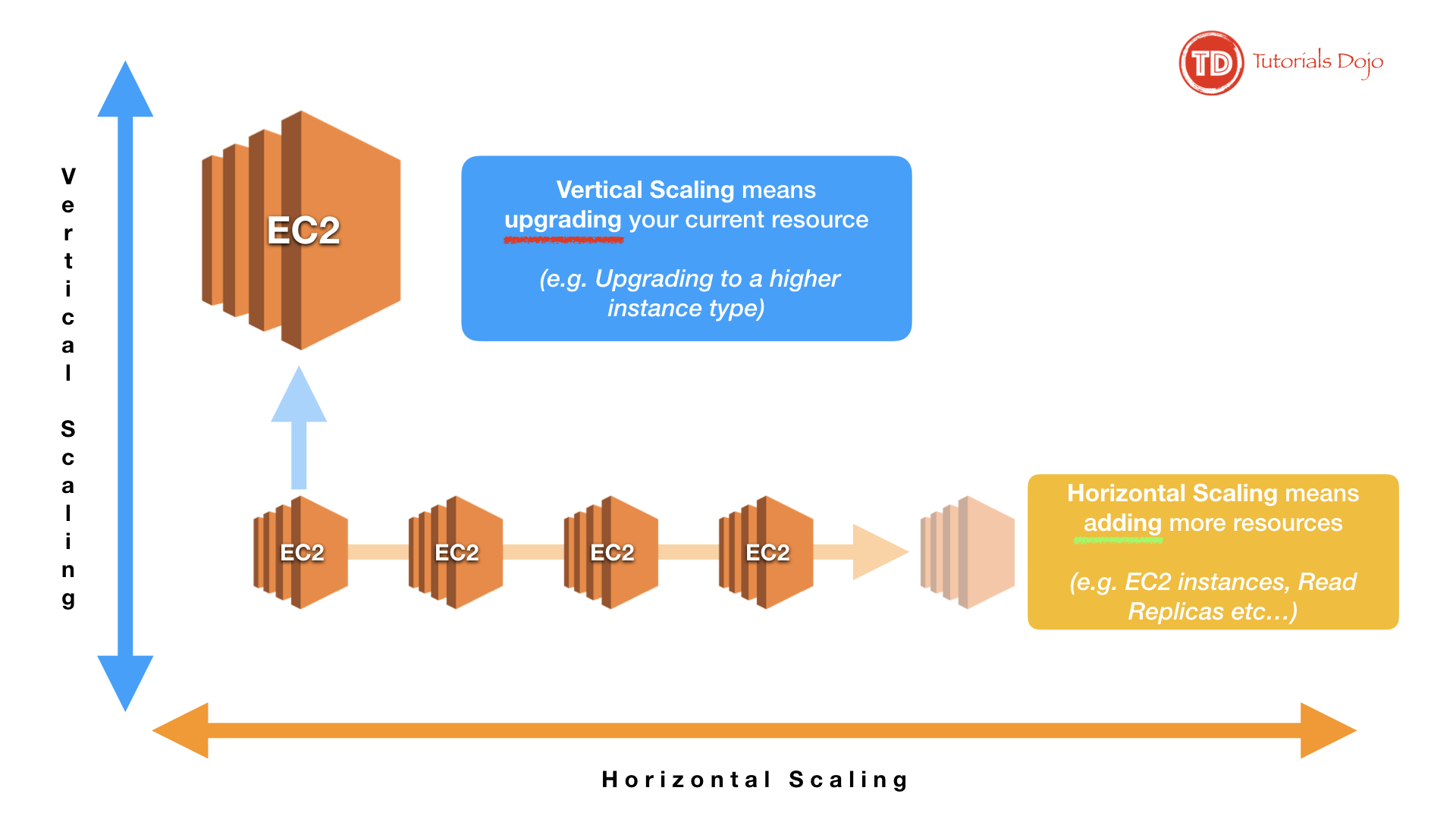
Vertical scaling vs Horizongal scaling
16.2.6. Test axioms¶
- If data is unstructured, Amazon S3 is generally the storage solution.
- Use caching strategically to improve performance.
- Know when and why to use Auto Scaling.
- Coose the instance and database type that makes the most sense for your workload and performance need.
16.3. Domain 3: Specify Secure Applications and Architectures¶
16.3.1. 3.1 Determine how to secure application tiers¶
16.3.2. 3.2 Determine how to secure data¶
We can break down the problem of securing data into 2 problems:
- Data in transit when data moves in and out of AWS or within AWS.
- Data at rest when data is stored in Amazon S3 or EBS or some other systems in AWS.
16.3.2.1. Data in transit¶
For securing the transfer of dara in and out of your AWS infrastructure, you can use:
- SSL over web.
- VPN for IPSec for data moving between corporate data centers and AWS.
- IPSec over AWS Direct Connect.
- Import/Export services via Snowball and Snowball mobile that keep the data encrypted.
In Data sent to the AWS API, the AWS API calls use HTTPS/SSL by default.
16.3.2.2. Data at rest¶
Data stored at Amazon S3 is private by default, it requires AWS credentials for access. It can be accessed over HTTP or HTTPS. There is an audit mode of access to all objects. It supports ACL and policies over buckets, prefixes (directory/folder) and objects. There are several options for encryption to choose on:
Server-side encryption. Request Amazon S3 to encrypt your object before saving it on disks in its data centers and then decrypt it when you download the objects. Options:
- Amazon S3-Managed keys (SSE-S3).
- KMS-Managed keys (SSE-KMS).
- Customer-provided keys (SSE-C)
Client-side encryption that requires encrypting the data before sending it to AWS service. Encrypt data client-side and upload the encrypted data to Amazon S3. In this case, you manage the encryption process, the encryption keys, and related tools. Options:
- KMS managed master encryption keys (CSE-KMS). When using an AWS KMS-managed customer master key to enable client-side data encryption, you provide an AWS KMS customer master key ID (CMK ID) to AWS.
- Customer managed master encryption keys (CSE-C). Your client-side master keys and your unencrypted data are never sent to AWS. It’s important that you safely manage your encryption keys because if you lose them, you can’t decrypt your data. Sometimes the CSE-C is required for strict compliance and regulatory requirements of the company.
You can store keys using:
- Key Management Service which is a customer software-based key management integrated with many AWS services (for instance Amazon EBS, S3, RDS, Readshift, Elastic Transcode, WorkMail, EMR) and you can use it directly from application.
- AWS CloudHSM which is a HW-based key management that you can use it directly from application and it is FIPS 140-2 compliant.
16.3.3. Test axioms¶
- Lock down the root user.
- Security groups only allow. Network ACLs allow explicit deny.
- Prefer IAM roles to access keys.
16.3.4. 3.3 Define the networking infrastructure for a single VPC application¶
It is reccommended to use subnets to define Internet accessibility.
- Public subnets. To support inbound/outbound access to the public Internet, include a routing table entry to an internet gateway.
- Private subnets. They do not have a routing table entry to an internet gateway. It is not directly accessible from the public Internet. To support restricted, outbound-only public Internet access, typically use a “jump box” (NAT/proxy/bastion host).
There are 2 main mechanisms to restricting access to a VPC: Security groups and Network ACLs.

Security groups versus Network ACLs
The different tiers of an application can be separated through security groups. You can use security groups to control traffic into, out of, and between resources.
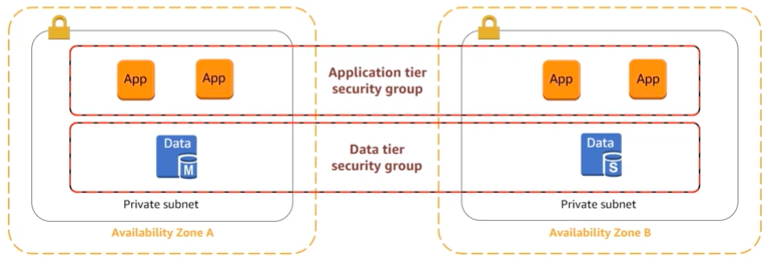
Security groups
The services to get traffic in or out of a VPC are:
- Intenet Gateway: It enables connecting to the Internet.
- Virtual Private Gateway: It enables connecting to customer’s data center through a VPN.
- Direct Connect: It sets up a Dedicted pipe between customer’s data center and AWS.
- VPC peering: It enables connecting VPCs to each others.
- NAT gateways: It allows Internet traffic from private subnets.
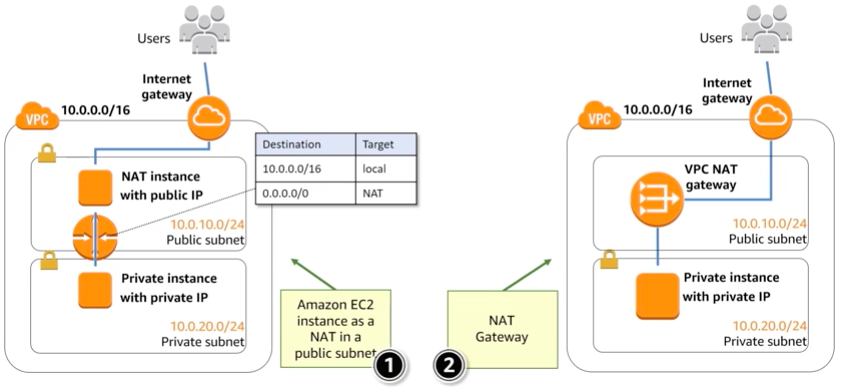
Outbound traffic from private instances
The NAT gateway is more scalable than a NAT instance and it is managed service. A NAT instance is cheaper because it is a single instance.
AWS re:Invent 2018: Your Virtual Data Center: VPC Fundamentals and Connectivity Options (NET201)
16.4. Domain 4: Design Cost-Optimized Architectures¶
16.4.1. 4.1 Determine how to design cost-optimized storage¶
Considerations for estimating the cost of using Amazon S3 are the following:
- Storage class.
- Storage amount.
- Number of requests.
- Amount of data transfer.
Considerations for estimating the cost of using Amazon EBS are the following:
- How many and what type of volumes.
- Input/output operations per second (IOPS)
- How frequently I am making snapshots and how long I am storing these snapshots.
- Data transfer.
16.4.2. 4.2 Determine how to design cost-optimized compute¶
Considerations for estimating the cost of using Amazon EC2 are the following:
- Clock hours of server time.
- Machine configuration.
- Machine purchase type.
- Number of instances.
- Load balancing.
- Detailed monitoring.
- Auto Scaling.
- Elastic IP addresses.
- Operating systems and software packages.
Amazon EC2 pricing factor are the following:
- EC2 instance families.
- Tenancy: default or dedicated
- Pricing options.
Note
Instance storage.
Instance storage is free but is ephemeral.
16.4.2.1. Serverless architectures¶
Another way to save cost is by using serverless architectures. In these architectures, you don’t pay for the idle time. The compute logic could be through AWS Lambda, static content via Amazon S3, Amazon DynamoDB for storing state, and Amazon API Gateway to attach a REST endpoint to Lambda that can be called via Web from a browser or other HTTP client.
16.4.2.2. Amazon CloudFront¶
CloudFront can help reduce your costs by avoiding fetching S3 data by caching it on CloudFront. Considerations for estimating the cost of using Amazon CloudFron are the following:
- Traffic distribution.
- Requests.
- Data transfer out.
Caching with CloudFront can have positive impacts on both performance and cost-optimization.
16.4.3. Test axioms¶
- If you know it’s going to be on, reserve it.
- Any unused CPU time is a waste of money.
- Use the most cost-effective data storage service and class.
- Determine the most cost-effective EC2 pricing model and instance type for each workload.
16.5. Domain 5: Define Operationally-Excellent Architectures¶
16.5.1. 5.1 Choose design features in solutions that enable operational excellence¶
16.5.2. Test axioms¶
- IAM roles are easier and safer than keys and passwords.
- Monitor metrics across the system.
- Automate responses to metrics where appropriate.
- Provide alerts for anomalous conditions.