2. Introduction¶
2.1. Cloud computing¶
In this section, I outline the definition of cloud computing given by NIST and map its essential characteristics, service and deployment models with the AWS offering.
2.1.1. Definition¶
The National Institute of Standards and Technology (NIST) comprehensively outlined the definition of Cloud Computing in their September 2011 NIST SP 800-145 publication:
Cloud computing is a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction.
This cloud model is composed of five essential characteristics, three service models, and four deployment models.
2.1.2. Essential Characteristics¶
2.1.2.1. 1. On-demand self-service¶
A consumer can unilaterally provision computing capabilities, such as server time and network storage, as needed automatically without requiring human interaction with each service provider.
To access Amazon Web Services (AWS) Cloud services, you can use the AWS Management Console, the AWS Command Line Interface (CLI), or the AWS Software Development Kits (SDKs). These services are provisioned automatically without any human intervention from AWS staff.
When you create a user, that user has no permissions by default. To give your users the permissions they need, you attach policies to them. It applies also to controlling user access to the AWS Management Console, AWS CLI or AWS SDKs.
2.1.2.2. 2. Broad network access¶
Capabilities are available over the network and accessed through standard mechanisms that promote use by heterogeneous thin or thick client platforms (e.g., mobile phones, tablets, laptops, and workstations).
The AWS Management Console has been designed to work on tablets as well as other kinds of devices:
- Horizontal and vertical space is maximized to show more on your screen.
- Buttons and selectors are larger for a better touch experience.
The AWS Management Console is also available as an app for Android and iOS. This app provides mobile-relevant tasks that are a good companion to the full web experience. For example, you can easily view and manage your existing Amazon EC2 instances and Amazon CloudWatch alarms from your phone.
You can download the AWS Console mobile app from Amazon Appstore, Google Play, or iTunes.
2.1.2.3. 3. Resource pooling¶
The provider’s computing resources are pooled to serve multiple consumers using a multi-tenant model, with different physical and virtual resources dynamically assigned and reassigned according to consumer demand. There is a sense of location independence in that the customer generally has no control or knowledge over the exact location of the provided resources but may be able to specify location at a higher level of abstraction (e.g., country, state, or datacenter). Examples of resources include storage, processing, memory, and network bandwidth.
secGlobalInfrastructure
2.1.2.4. 4. Rapid elasticity¶
Capabilities can be elastically provisioned and released, in some cases automatically, to scale rapidly outward and inward commensurate with demand. To the consumer, the capabilities available for provisioning often appear to be unlimited and can be appropriated in any quantity at any time.
secAWSAutoScaling monitors your applications and automatically adjusts capacity to maintain steady, predictable performance at the lowest possible cost. Currently, the supported applications are: secECS, secEMR, secEC2, secAppStream, secDynamoDB, secRDS, secSageMaker, secComprehend.
Any service that you build with adjustable resource capacity can be automatically scaled using the new Custom Resource Scaling feature of Application Auto Scaling. To use Custom Resource Scaling, you register an HTTP endpoint with the Application Auto Scaling service, which will use that endpoint to scale your resource.
2.1.2.5. 5. Measured service¶
Cloud systems automatically control and optimize resource use by leveraging a metering capability [1]_ at some level of abstraction appropriate to the type of service (e.g., storage, processing, bandwidth, and active user accounts). Resource usage can be monitored, controlled, and reported, providing transparency for both the provider and consumer of the utilized service.
secCloudWatch monitors your AWS resources and the applications you run on AWS in real time. You can use CloudWatch to collect and track metrics, which are variables you can measure for your resources and applications. A namespace is a container for CloudWatch metrics. For the list of AWS namespaces, see AWS Services That Publish CloudWatch Metrics.
CloudWatch ServiceLens enhances the observability of your services and applications by enabling you to integrate traces, metrics, logs, and alarms into one place. ServiceLens integrates CloudWatch with AWS XRay to provide an end-to-end view of your application to help you more efficiently pinpoint performance bottlenecks and identify impacted users. A service map displays your service endpoints and resources as “nodes” and highlights the traffic, latency, and errors for each node and its connections. You can choose a node to see detailed insights about the correlated metrics, logs, and traces associated with that part of the service. This enables you to investigate problems and their effect on the application.

Service Map
You can use Event history in the secCloudTrail console to view, search, download, archive, analyze, and respond to account activity across your AWS infrastructure. This includes activity made through the secConsole, secCLI, and AWS SDKs and APIs. CloudTrail is enabled by default for your AWS account.
| [1] | Typically this is done on a pay-per-use or charge-per-use basis. |
2.1.3. Service Models¶
2.1.3.1. Software as a Service (SaaS)¶
The capability provided to the consumer is to use the provider’s applications running on a cloud infrastructure [2]_. The applications are accessible from various client devices through either a thin client interface, such as a web browser (e.g., web-based email), or a program interface. The consumer does not manage or control the underlying cloud infrastructure including network, servers, operating systems, storage, or even individual application capabilities, with the possible exception of limited userspecific application configuration settings.
AWS offers SaaS solutions through AWS Marketplace. AWS Marketplace is a digital catalog with thousands of software listings from independent software vendors that make it easy to find, test, buy, and deploy software that runs on AWS.
2.1.3.2. Platform as a Service (PaaS)¶
The capability provided to the consumer is to deploy onto the cloud infrastructure consumer-created or acquired applications created using programming languages, libraries, services, and tools supported by the provider [3]_. The consumer does not manage or control the underlying cloud infrastructure including network, servers, operating systems, or storage, but has control over the deployed applications and possibly configuration settings for the application-hosting environment.
AWS has a PaaS service called secBeanstalk.
2.1.3.3. Infrastructure as a Service (IaaS)¶
The capability provided to the consumer is to provision processing, storage, networks, and other fundamental computing resources where the consumer is able to deploy and run arbitrary software, which can include operating systems and applications. The consumer does not manage or control the underlying cloud infrastructure but has control over operating systems, storage, and deployed applications; and possibly limited control of select networking components (e.g., host firewalls).
Most of AWS services are IaaS.
| [2] | A cloud infrastructure is the collection of hardware and software that enables the five essential characteristics of cloud computing. The cloud infrastructure can be viewed as containing both a physical layer and an abstraction layer. The physical layer consists of the hardware resources that are necessary to support the cloud services being provided, and typically includes server, storage and network components. The abstraction layer consists of the software deployed across the physical layer, which manifests the essential cloud characteristics. Conceptually the abstraction layer sits above the physical layer. |
| [3] | This capability does not necessarily preclude the use of compatible programming languages, libraries, services, and tools from other sources. |
2.1.4. Deployment Models¶
- Private cloud. The cloud infrastructure is provisioned for exclusive use by a single organization comprising multiple consumers (e.g., business units). It may be owned, managed, and operated by the organization, a third party, or some combination of them, and it may exist on or off premises.
- Community cloud. The cloud infrastructure is provisioned for exclusive use by a specific community of consumers from organizations that have shared concerns (e.g., mission, security requirements, policy, and compliance considerations). It may be owned, managed, and operated by one or more of the organizations in the community, a third party, or some combination of them, and it may exist on or off premises.
- Public cloud. The cloud infrastructure is provisioned for open use by the general public. It may be owned, managed, and operated by a business, academic, or government organization, or some combination of them. It exists on the premises of the cloud provider.
- Hybrid cloud. The cloud infrastructure is a composition of two or more distinct cloud infrastructures (private, community, or public) that remain unique entities, but are bound together by standardized or proprietary technology that enables data and application portability (e.g., cloud bursting for load balancing between clouds).
Most of AWS Services are provisioned using a Public cloud deployment model. However, AWS Outposts bring native AWS services, infrastructure, and operating models across on premises and the AWS cloud to deliver a truly consistent hybrid experience. AWS Outposts is designed for connected environments and can be used to support workloads that need to remain on-premises due to low latency or local data processing needs.
AWS Outposts come in two variants:
- VMware Cloud on AWS Outposts allows you to use the same VMware control plane and APIs you use to run your infrastructure.
- AWS native variant of AWS Outposts allows you to use the same exact APIs and control plane you use to run in the AWS cloud, but on premises.
AWS Outposts infrastructure is fully managed, maintained, and supported by AWS to deliver access to the latest AWS capabilities. Getting started is easy, you simply log into the AWS Management Console to order your Outpost, choosing from a wide catalog of Amazon EC2 instances and capacity and EBS storage options.
2.1.5. Six advantages of cloud computing¶
Six Advantages of Cloud Computing
The Six Main Benefits of Cloud Computing with Amazon Web Services
2.1.5.1. AWS cloud benefits¶
- No up-front investment
- Low on-going costs
- Focus on innovation
- Flexible innovation
- Speed and agility
- Global reach on demand
2.1.5.2. On-premises considerations¶
- Large upfront capital expense
- Labor, patches and upgrade cycles
- System administration
- Fixed capacity
- Procurement and setup
- Limited geographic regions
2.2. Overview of Amazon Web Services¶
Overview of Amazon Web Services
2.2.1. AWS products and services¶

2.2.1.1. The management continuum¶
It is important to consider how much of the infrastructure the customer wants to manage.
- On one end of the management continuum is a self-managed infrastructure. In this approach, the customer manages the entirety of the infrastructure stack, including the hardware, the software, hypervisor, operating systems, applications, network, patching, upgrades, real state, power, cooling and staffing. This is the approach customers take when they manage their own data centers.
- The next level is a partially managed service, like Amazon EC2. When a customer chooses EC2, they only need to manage the OS and software applications. In essence, the customer manages their virtual machine and AWS takes care ofthe rest. The customer can choose the amount of resources to allocate to a virtual machine, including CPU, memory, network, and storage amounts, as well as other configuration options, such as the inclusion of GPUs.
- On the other end of the management continuum, the customer can opt for a fully managed service, such as Amazon RDS. In this case, the customer can focus on the characteristics of the service and not on the infrastructure being used to deliver the service.
As the customer moves across the management continuum, they increasingly shift their focus away from infrastructure and more toward the application.
2.2.1.2. Managed services¶
An architectural consideration unique to cloud solutions is service scope. The scope of any AWS service falls into one of 3 categories: global, regional or zonal.
- An instance of a global service, such as Amazon Route 53, spans the entire AWS global infrastructure, including all Regions simultaneously.
- An instance of a regional service, such as Amazon Aurora managed database service, is contained in a single AWS Region, but it can span all AZs simultaneously.
- An instance of a zonal service. such as Amazon EC2, is contained in a single AZ.
2.2.2. AWS pricing¶
2.2.2.1. AWS cost fundamentals¶
There are 3 fundamental characteristics you pay for with AWS: compute capacity, storage and outbound data transfer. The outbound data transfer is aggregated across Amazon EC2, S3, RDS, SimpleDB, SQS, SNS, and VPC and then charged at the outbound data transfer rate. These characteristics vary depending on the AWS product you are using. This charge appears on the monthly statement as AWS Data Transfer Out. There are no charge for inbound data transfer between other services within the same region.

Pricing characteristics
Prices for many services are tiered, so that you get a volume discount. The more you use it, the cheaper the service you get.
2.2.2.2. Consumption-based model¶
With a consumption-based model, AWS customers pay only for what they use rather than pay upfront for what they think they will need in the future.
When a customer overprovisions, they order more servers than they need, and they end up with unused resources. When a customer underprovisions, they order too few servers and fail to deliver on their SLAs. In both cases, the trade-off is inefficiency and financial loss.
AWS helps their customers avoid inefficiencies and financial losses by enabling their customers to launch the infrastructure they need when they need it. With this model, overprovisioning and underprovisioning are no longer issues. Customers align their infrastructure, services, and costs to usage patterns.
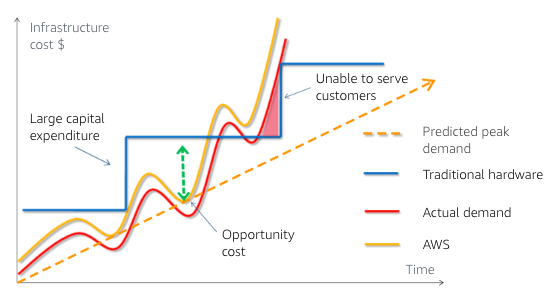
Provisioning infrastructure
2.2.2.3. AWS pricing models¶
AWS pricing models offer a second way AWS can help their customers lower costs. Customers can buy from traditional vendors using various payment plans, yet in the end, they are stuck with the same set of servers until their next refresh. With AWS, customers can optimize the usage model to the requirements of workloads by maturity and behavior.
By maturity, we mean, “Does the customer have enough data to determine a usage baseline so they can use a Reserve Instance?” When we say behaviour, we mean, “Is data usage too spiky for Reserved Instances? Will Spot Instances work better?”.
Typically, customers start with On-Demand Instances to gauge their needs, and then switch to Reserved Instances (RIs), once they know their demand baseline. Reserved Instances reduce costs by up to 75% versus On-Demand.
AWS excess capacity sold for a deep discount is call a Spot Instance.
Finally, for customers with regulatory or software licensing constraints who need their own hosts, AWS provides Dedicated Hosts.
2.2.2.4. Tools¶
- Simple monthly calculator. It will be replacing by AWS Pricing Calculator
- Each AWS service has a detailed pricing page.
- To programmatically access pricing details, use the AWS Price List API. Customers can set up notifications to receive alerts when AWS changes prices, such as for adds, updates, and removals.
- AWS Cost Explorer has improved trend-based forecasting, based on machine learning, and rules-based models to predict spend across charge types.
2.2.2.5. Frequent price reductions¶
The third way AWS lower costs is by continually reducing prices. AWS operates on a massive scale, allowing them to increase efficiencies and reduce costs. AWS then pass the savings to their customers through price reductions. Every time AWS reduces its prices, all AWS customers experience the savings immediately.
When price reductions occur, customers automatically receive the lower prices. They never need to call AWS, contact an account manager, renegotiate a contract, or ask for the price reduction.
One exception to price reductions is Reserved Instances. RIs are already heavily discounted with prices accounting for forecasted future discounts. With planning, customers can benefit from both worlds.
2.2.2.6. Amazon flywheel¶
The Amazon flywheel, created by Jeff Bezos shows the Amazon business model of scale. It illustrates how the Amazon high-volume, low-margin business model works. As you can see, it’s a positive feedback loop driven by price reductions.
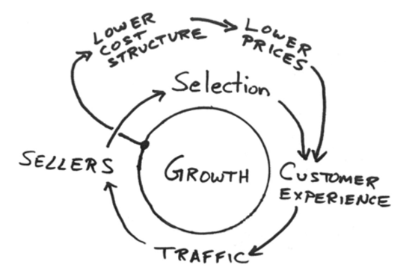
Amazon flywheel
This is the AWS version of the Amazon flywheel. AWS offers lower prices, which means more customers will use AWS patforms. AWS then increases its infrastructure size, which improves AWS economies of scale. AWS can then lower infrastructure costs and lower prices for customers again. And this cycle continues.
Another aspect of economies of scale is that AWS can offer services that a company might not be able to develop, support, or run in an efficient manner. These services might be relevant for only a limited number of customers, or they might not make sense for customers to develop on their own, yet with AWS scale, the srvices ecome inexpensive and easy-to-use. By using AWS, companies can focus more on innovation and less on infrastructure.

AWS flywheel
2.2.2.7. Resources for cost analysis¶
TSO Logic was acquired December 2018 by Amazon for their ability to quickly deilver an optimized business case for AWS. TSO Logic’s analytics software gives customers the answers they need to make soung cloud planning, migration, and modernization decisions. Offered as a service, TSO Logic gives customers an understanding of how much compute they have, how it’s used, what it costs to operate, and the projected costs of running on AWS. It also shows where on-premises instances are overprovisioned and where alternate AWS placements can meet or exceed those requirements at a lower cost. TSO Logic is available to AWS APN Partners based on certaing qualifications.
Migration Portfolio Assessment (MPA) tool include the following key features:
- Guided data ingestion.
- Right-sized EC2 instance and storage recommendations based on performance profiles.
- Run rate cost comparisons between current state and recommended AWS.
- Over 100 variables with pre-propulated industry defaults to help dial in current costs, migration costs, and future run rates.
- Migration pattern analysis and recommendations.
- Migration project estimating for resources, timelines, and costs.
- Customizable dashboards to visualize data.
- Secure access for Advanced and Premier tier AWS APN Partners.
2.2.3. Security of the cloud¶
2.2.3.1. AWS compute security¶
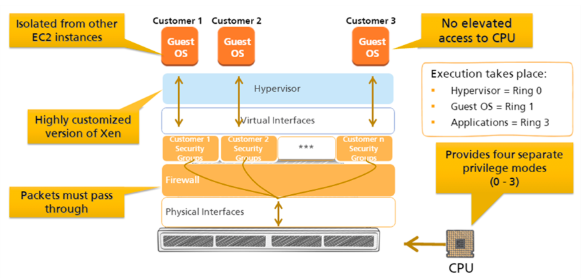
2.2.3.2. AWS memory and storage protection¶
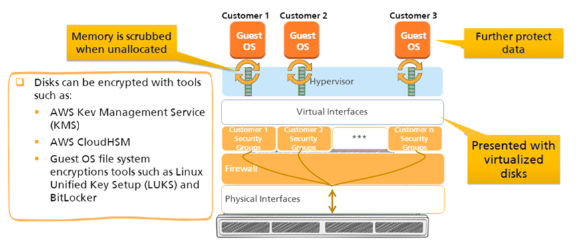
2.2.3.3. Database security¶

2.2.4. AWS Support Plans¶
AWS support offers 4 support plans:
- Basic support.
- Developer support.
- Business support.
- Enterprise support.
2.3. The AWS Well-Architected Framework¶
AWS Well-Architected Framework
AWS Well-Architected Framework whitepaper
The AWS Well-Architected Framework covers:
- Strategies and best practices for architecting in the cloud.
- It provides you with a way to measure your architecture against AWS best practices.
- Identifies how to address any shortcomings.
The AWS Well-Architected Framework enables the customer:
- To make informed decisions about their architecture.
- Think in a cloud-natively way.
- Understand the impact of design decisions that are made.
The purposes of AWS Well-Architected Framework are the following:
- Increases awareness of architectural best practices.
- Addresses foundational areas that are often neglected.
- Provides a consistent approach to evaluating architectures
It is composed of Questions, Pillars and Design Principles.
2.3.1. General design principles¶
The AWS Well-Architected Framework includes many best-practices design principles for AWS solutions. These principles may be general, such as the importance of enabling traceability. But hey also include pillar-specific design principles, such as maintaining defining security responses based on traced information, an automating responses when possible.
The general design principles in a on-premises environment are:
- You have to guess the infrastructure needs. It is often based on high level business requirements and demand and often before a line of code is written.
- You cannot afford to test at scale. A complete duplicate of production costs is hard to justify, especially with low utilization. So when you go to production, you normally find a whole new class of issues at high scale.
- You fear make significant architectural changes because you do not have no way to test it properly. It would stop you from delivering other features because of your environment is single pipeline.
- Experiments were PoC at the start. It is hard to justify later due to the effort of getting resources to try different things out. You manually build and customize which is hard to reproduce.
- Your architecture is frozen in time. Eventhough everything progresses, such as your user are doing, the requirements and even the business model.
The general design principles in an AWS environment are different. Customers can:
- Stop guessing capacity needs.
- Test systems at production scale.
- Automate to make experimentation easier.
- Allow architectures to evolve.
- Build data-driven architectures.
- Improve through game days.
A workload is defined as a collection of interrelated applications, infrastructure, policy, governance, and operations running on AWS that provide business or operational value.
2.3.2. Security¶
Security is the ability to protect information, systems, and assets while delivering business value through risk assessments and mitigation strategies. The focus areas are:
- Identity and access management
- Detective controls
- Infrastructure protection
- Data protection
- Incident response
2.3.2.1. Design Principles¶
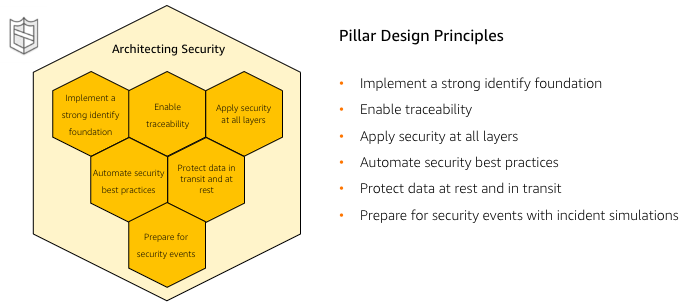
- Implement security at all layers
- Enable traceability: To log and audit all actions and changes to an environment, to automatically respond and take action.
- Apply principle of least privilege: persons (or processes) can perform all activities they need to perform, and no more.
- Focus on securing your system
- Automate responses to security events
2.3.3. Reliability¶
Reliability is the ability of a system to recover from infrastructure or service failures, dynamically acquire computing resources to meet demand, and mitigate disruptions, such as misconfigurations or transient network issues. The focus areas are:
- Foundations
- Change management
- Failure management
Chaos Monkey is a Netflix resiliency tool that helps applications tolerate random instance failures.
Bees with Machine Guns! is a utility for arming (creating) many bees (micro EC2 instances) to attack (load test) targets (web applications).
2.3.3.1. Design Principles¶

- Test recovery procedures
- Automatically recover
- Scale horizontally
- Stop guessing capacity
- Manage change in automation
2.3.4. Cost Optimization¶
Cost Optimization is the ability to avoid or eliminate unneeded cost or suboptimal resources. The focus areas are:
- Use cost-effective resources
- Matched supply and demand
- Increase expenditure awareness
- Optimize over time
2.3.4.1. Design Principles¶
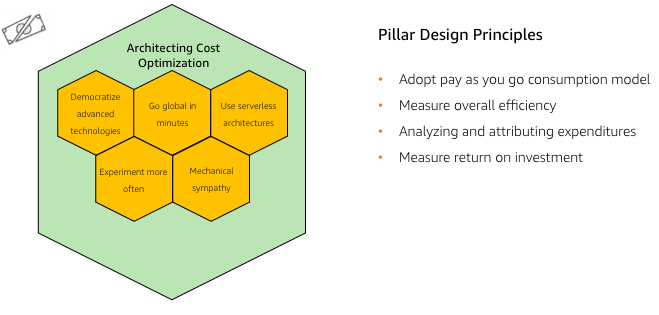
- Adopt a consumption model
- Measure overal efficiency
- Reduce spending on data center operations
- Analyze and attricute expenditure
- Use manage services
2.3.5. Operational Excellence¶
Operational Excellence is the ability to run and monitor systems to deliver business value, and continually improve supporting processes and procedures.
Its key service is AWS CloudFormation. You can have IaC and the CloudFormation templates are correct documentation of your environment.
The focus areas and their key tools are:
Prepare:
- Understand the business goals they are trying to achieve and set up operational priorities to support these goals and use these priorities to focus their operational improvement efforts where they have the greatest impact.
- Design for operations is focused on architecting for runtime. This includes making architectural design decisions that would enable deployments of your workloads using techniques that mitigate deployment risks and allow you to reduce defects and fix or workaround them safely in production. It includes instrumenting your workloads to enable understanding of their operational health and enable useful businesses and technical insights. Ideally, design standards and templates should be established and shared across organizations to simplify development efforts and reduce duplication effort.
- Operational readiness is focused on validating the readiness of both the workloads into production and the operational team to support the workload in production. Evaluation of the workload includes consideration of your standards and governance conduct using checklists to ensure consistent evaluation. Review of the operational team including team size and skillset as well as the capture of procedures. Routine operations procedures should be capture in runbooks and processed for issue resolutuion in playbooks. Ideally, procedures should be scripted to increase consistency and execution, reduce the introduction of human error and to enable automation triggered in response to observed events.
Operate:
- Understangding the operational health of your workload. It is defined in the achievement of business and customer outcomes. You must define metrics to measure the behavior of the workload against expected outcomes. Metrics to measure the status of the workloads and their components and metrics to measure the execution of operations activities.
- Deriving business and technical insights. By establishing baselines and collecting and analysing these metrics you can evaluate operational health, gain business insights and identify areas for intervention or improvement.
- Responding to operational events. Both planned and unplaned operational events should be anticipated. Planned events may include may include sales promotions, deployments and game days. Unplanned events may include component failures. Runbooks and playbooks should be used to enable consistent response to events and to limit the introduction of human error.
Evolve: It is focused on dedicated work cycles to make continuous incremental improvement to your operations.
- Learn from experience. Customers should evaluate oportunities from improvements captured from feedback loops, lessons learned analysis and cross-team reviews.
Their key tools are:
- Prepare: AWS Config and AWS Config Rules can be used to create standards for workloads and determine if environment are compliant with standards before putting them into production.
- Operate: Amazon CloudWatch to monitor the operational health of the workload
- Evolve: Amazon Elasticsearch to analyze log data and get actionable insights quickly and securely.
2.3.5.1. Design Principles¶

Operational excellence design in an on-premises environment:
- Most changes are made by human beings following runbooks that are often out of date.
- It is easy to be focused on the technology metrics rather than business outcomes.
- Because making changes are difficult and risky you tend to want them often and therefore tend to batch changes into large releases.
- You rarely simulate failures or events because tou do not have the system or human capacity to do this.
- Often things are moving so fast that you move from one reactive situation to the next, with no time to learn from mistakes.
- Dure to the rate of change it becomes to keep documentation current.
Operational excellence design in an AWS environment:
- Performs operations by code with business metrics with you can measure against.
- Annotated documentation.
- By automating change and using code, you can make frequent, small and reversible changes.
- Refine operations procedures frequently by making game days and detecting failures in procedures.
- Learn from these and other operational events to improve your responses.
- Anticipate failure. Because infrastructure is code, you can detect when documentation is out of date and even generate documentation and include annotations to enable its use and automation.
2.3.6. Performance efficiency¶
Performance efficiency is the ability to use computing resources efficiently to meet system requirements, and to maintain that efficiency as demand changes and technologies evolve. The focus areas are:
- Select customizable solutions
- Review to continually innovate
- Monitor AWS services
- Consider the trade-offs
2.3.6.1. Design Principles¶
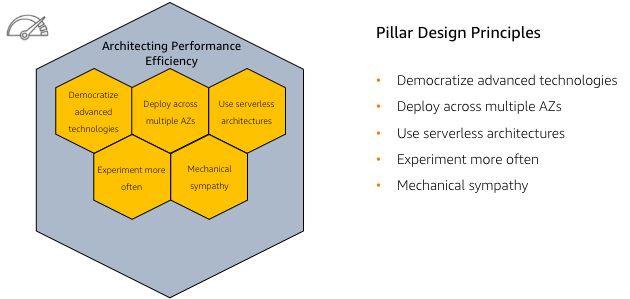
- Democratize advanced technologies
- Go global in minutes
- Use a serverless architecture
- Experiment more often
- Have mechanical sympathy
2.3.7. AWS Well-Architected Tool¶
The AWS Well-Architected Tool helps you review your workloads against current AWS best practices and provides guidance on how to improve your cloud architectures. This tool is based on the AWS Well-Architected Framework. The AWS Well-Architected Framework has been developed to help cloud architects build secure, high-performing, resilient, and efficient infrastructure for their applications. Based on five pillars — operational excellence, security, reliability, performance efficiency, and cost optimization. — the Framework provides a consistent approach for customers and partners to evaluate architectures, and implement designs that will scale over time.
This is a free tool, available in the AWS Management Console. The process to evaluate a workload consists of 3 steps:
- Define a workload by filling information about the architecture: name, a brief description to document its scope and intented purpose, the environment (production or pre-production), AWS Regions and Non-AWS Regions in which the workload runs, Account IDs (optional), industry type (optional) and industry (optional).
- Document the Workload State by answering a series of questions about your architecture that span the pillars of the AWS Well-Architected Framework: operational excellence, security, reliability, performance efficiency, and cost optimization. After documenting the state of your workload for the first time, you should save a milestone and generate a workload report. A milestone captures the current state of the workload and enables you to measure progress as you make changes based on your improvement plan.
- Review the Improvement Plan. Based on the best practices you selected, AWS WA Tool identifies areas of high and medium risk as measured against the AWS Well-Architected Framework. The Improvement items section shows the recommended improvement items identified in the workload. The questions are ordered based on the pillar priority that is set, with any high risk items listed first followed by any medium risk items.
- Make Improvements and Measure Progress. After deciding what improvement actions to take, update the Improvement status to indicate that improvements are in progress. After making changes, you can return to the Improvement plan and see the effect those changes had on the workload.
2.3.8. Common uses¶
- Learn how to build cloud-native architectures.
- Build a backlog.
- Use a gating mechanism before launch.
- Compare maturity of different teams.
- Due-diligence for acquisitions.
2.4. AWS Global Infrastructure¶
2.4.1. AWS Data Centers¶
2.4.2. AWS Availability Zones¶
An Availability Zone (AZ) consists of several datacenters, all of them linked via intra-AZ connections and each with with redundant power supplies, networking and connectivity, housed in separated facilitiess. All AZ are connected among them through inter-AZ connections and to the exterior via Transit Center connections. AZs are represented by a region code followed by a letter identifier.
2.4.3. AWS Regions¶
AWS Global infrastructure interactive map

Intra-Region connectivity
AWS re:Invent 2016: Tuesday Night Live with James Hamilton
Choosing regions for your architectures:
Save yourself a lot of pain (and money) by choosing your AWS Region wisely